马慧娟 , 高小红, 谷晓天
, 高小红, 谷晓天
青海师范大学地理科学学院 青海省自然地理与环境过程重点实验室,西宁 810008
MA Huijuan, GAO Xiaohong, GU Xiaotian
通讯作者:
收稿日期: 2018-07-27
修回日期: 2018-12-27
网络出版日期: 2019-03-15
版权声明: 2019 《地球信息科学学报》编辑部 《地球信息科学学报》编辑部 所有
基金资助:
作者简介:
作者简介:马慧娟(1993- ),女,青海西宁人,硕士生,主要研究方向为遥感应用与地理空间数据分析。E-mail: 1298878942@qq.com
展开
摘要
随机森林方法目前已经成为遥感分类机器学习中一种有效方法,探索基于中等分辨率的Landsat卫星数据与随机森林方法相结合对复杂地形区长时间序列数据的获取及土地利用/土地覆被变化及模拟研究是非常有意义的。本文基于Landsat8OLI卫星多光谱数据,采用随机森林分类方法对青海省湟水流域复杂地形区土地利用类型进行了分类研究。针对复杂地形区域的情况,将研究区进行地理分区,根据每个分区的特点,选择相应的地形特征参数,并通过提取Landsat 8数据的光谱信息与纹理信息构建最优特征集,探索随机森林方法在复杂地形区土地利用分类的适用性。结果表明:使用Landsat8OLI数据进行随机森林分类,能较好地得到湟水流域复杂地形区域的土地利用类型结果;光谱、地形及纹理信息的结合在不同分区的表现结果不同。在脑山区光谱与地形信息结合能使随机森林分类效果最佳,总体精度达到91.33%,Kappa系数为0.886;而在浅山区与川水区综合考虑光谱、地形、纹理信息进行随机森林分类效果最佳,浅山区与川水区总体精度分别达到92.09%和87.85%,Kappa系数分别为0.902和0.859;利用随机森林算法进行优化选择纹理特征组合可以在保证分类精度的同时能够快速地提取土地利用类型信息,为复杂地形区土地利用类型的区分提供了实际可行的方法。
关键词:
Abstract
Random forest classification has become an effective method in remote sensing classification of machine learning. It is of great significance to combine the Landsat satellite data and random forest method to obtain long time series data in the complex terrain areas and to explore its land use/land cover change. Based on the multi-spectral data of landsat8 OLI satellite, this paper adopted the random forest classification method to classify the land use types of Huangshui basin complex topography areas in Qinghai province. According to the characteristics of complex terrain areas, the study area was divided into different geographical regions. The topographic parameters were then selected, and the optimal feature collection was constructed by extracting spectral and texture information of Landsat8 data. The objective of this papers was to explore the applicability of random forest methods in land use classification on the complex topographic regions. The results showed that RFC classification with the landsat8 OLI data can be well used to obtain the land use types in the Huangshui basin. The combination of spectral, topographic, and texture information performed differently in different areas. In the middle and high mountain areas, the combination of spectral and topographic information can obtain the best results in the random forest classification with the overall accuracy of 91.33% and Kappa coefficient of 0.886. In the shallow mountain areas and valley plain, however, the random forest classification can obtain the best results by combining spectral, topographic, and texture information with the overall accuracy of 92.09% and 87.85% and Kappa coefficient of 0.902 and 0.859, respectively. Using the random forest algorithm to optimize the selection of texture feature combination can extract the land use type information quickly and ensure its accuracy. Random forest classification combined multi-source information can be used effectively to classify land use types, which can provide some enlightenment and reference values for the renewal of land use status and the development of social economy in the study area.
Keywords:
基于遥感技术的土地利用/土地覆盖分类是遥感信息提取中的重要手段之一[1]。近年来,采用机器学习算法进行土地利用信息提取已经成为遥感应用研究的热点,如人工神经网络、支持向量机、决策树等方法都被广泛的应用[2,3,4]。由于学习算法的不断改进,遥感影像的分类得到了较好的效果。
随机森林算法是一种基于分治法原理的集成学习算法,因分类精度高,训练和预测速度快,可以处理高维数据等诸多的优点,它在遥感领域分类应用十分的广泛。Pal[5]将随机森林应用于LandsatETM+影像的土地利用信息提取,通过实验表明随机森林非常适合于土地利用分类。Chan和Desiré[6]比较了基于航空高光谱图像对生态区分类的三种分类方法,得出随机森林在训练中比Adaboost更快更稳定。Waske和Braun[7]以SAR数据为基础,利用随机森林进行平原地区土地覆盖分类,结果表明多时相数据中的不同信息对分类结果有着一定的影响。在国内,田邵峰和张显峰[8]针对干旱区采用随机森林算法将纹理特征与植被信息结合构建最优组合,建立有效的RFC分类器。结果表明采用随机森林法,利用经过优化选择后的特征组合对干旱区进行分类时总体精度提高近10%,满足了随机森林提取干旱区土地覆盖信息的需求。马玥等[9]将不同季节的Landsat8影像数据与光谱、地形特征等组合成多源数据,利用随机森林对农耕区进行了土地利用分类,讨论了基于重要性分析的特征参数选择方法,结果表明随机森林适用于包含多种特征的多源数据。以上研究大部分是地形相对简单的地区,对复杂地形区域来说利用随机森林进行土地利用信息提取的研究报道较少[10]。谷晓天[11]基于Landsat 8遥感影像数据,利用人工神经网络、决策树、支持向量机和随机森林4种机器学习方法进行了土地利用分类的对比研究。结果表明,随机森林相比其他3种方法在分类精度和分类效率方面更具优势,是地形复杂区遥感影像分类的有效方法。本文以复杂地形区湟水流域为例,参考曾永年等[12,13]、李金山[14]、贾伟等[15]的研究结果,结合野外实地调查,将湟水流域按照海拔高度划分为3个地理区,即中高山区、黄土丘陵区与河谷平原区(当地百姓依次称之为脑山区、浅山区以及川水区)。采用随机森林算法,基于光谱、纹理和地形信息对3个地理区的土地利用类型信息进行提取;根据脑山区、浅山区、川水区的特点加入不同的特征参数,构建最优特征参数集,以达到提高复杂地形区分类精度的目的。探索基于随机森林算法的综合光谱、纹理和地形信息在复杂地形区的湟水流域土地利用/土地覆盖分类中的适用性,为今后随机森林算法广泛应用于复杂地形区提供方法支持和实际应用。
研究区湟水流域位于青海省东北部,地处青藏高原与黄土高原过渡带,地理位置36°02′N-37°28′N,100°42′E-103°04′E,面积为16 120 km2,区域海拔1655~4860 m(图1)。
图1 研究区概况与采样点分布
Fig. 1 Location of the study area and distribution of sampling site
地貌类型涉及河谷平原、黄土丘陵以及中、高山地。该流域气候为温带大陆性气候,多年平均气温一般在2.7~7.8 ℃,年降水量大约为200~910 mm。土地利用类型种类多样,主要有水浇地、坡耕地、草地、林地、水体、未利用土地,城乡工矿居民用地。农作物有小麦、油菜、青稞、燕麦、玉米、蚕豆、马铃薯等。
2.2.1 数据来源
本文采用影像空间分辨率为30 m的Landsat8多光谱数据,为保证分类效果,主要以2016年7-8月且云量低于3%的影像为主,以2015年和2014年影像作为补充,具体影像信息如表1所示。并获取7景数字高程模型数据。
表1 影像数据信息
Tab. 1 Image data information
| 影像编号 | 接收卫星 | 传感器类型 | 影像获取时间 | 分辨率/m | 波段数 |
|---|---|---|---|---|---|
| LC81330342016211LGN00 | Landsat8 | Operational Land Image (OLI) | 2016-07-29 | 30 | 2-7波段 |
| LC81310352016213LGN00 | 2016-07-31 | ||||
| LC81320342015233LGN00 | 2015-08-21 | ||||
| LC81320352014198LGN00 | 2014-07-17 |
2.2.2 数据预处理
Landsat8 OLI多光谱影像数据:首先利用ENVI 5.3中Radiometric Calibration工具对其进行辐射定标,其次采用大气校正Flash模型进行大气校正;将校正后的4景影像进行图像镶嵌,最后,再按照研究区的范围进行图像裁剪。由于遥感影像获取时间不一致,为了保证镶嵌时影像色彩差异较小,对影像进行图像增强处理,主要采用辐射增强与光谱增强。辐射增强通过对单个像元的灰度值进行变换达到增强处理目的,每景影像分别选择了1%、2%、5%的线性拉伸处理,通过比较,4景影像均选择目视效果最佳的2%线性拉伸进行图像镶嵌。光谱增强基于多光谱数据对波段进行变换达到图像增强处理,主要选用标准假彩色543波段组合、主成分分析以及NDVI的计算,提高图像的目视效果,以便于图像分类中样本的选取等。该影像投影类型为UTM(zone48)/WGS84。DEM地形数据:首先将获取的7景数字高程模型数据分别进行填洼处理、其次将填洼处理后的7景DEM数据进行图像镶嵌,再按照湟水流域的范围进行裁剪,最后与采用的Landsat8OLI影像统一投影参数。
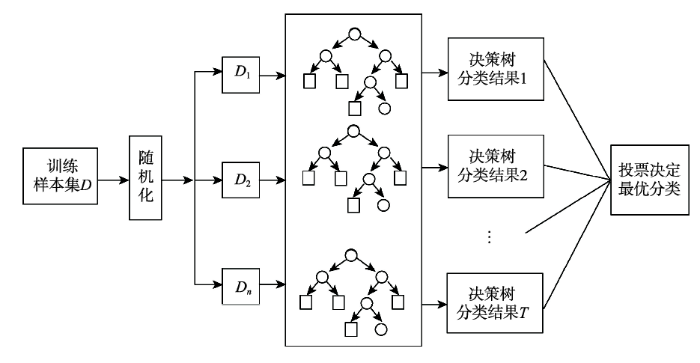
随机森林(Random Forest, RF)算法是2001年由Breiman提出的一种分类模型[16]。它由若干决策树集成,利用多棵树对样本进行训练并预测,最终分类结果由多棵树分类器投票决定[17],如图2所示。
随机森林构建过程:首先采用Bootstrap自助 抽样技术随机有放回采样选出N个训练集,每个训练集大小约为原始训练集的2/3,剩余1/3为袋外数据[18,19]。其次,把每个自助样本集训练生成单个决策树,并从样本特征的总数M个中随机挑选m个特征变量作为预测变量,每次分裂时根据Gini系数最小原则选择最优的特征进行分裂,每棵树一直分裂下去不需要修剪,直到该节点的所有训练样例都属于同一类[20,21,22];最后,组合N棵决策树的预测,由按多棵树分类器投票的方式决定最终预测结果[23,24]。
在随机森林构建过程中设置以下2个参数:决策树的个数N,当N≥100时,各分类情况的OOB误差趋于稳定,随机森林未出现过拟合的现象,因此设置决策树N=100;随机特征变量个数m,本文根据Breiman建议设定m(随机特征变量的个数)等于M(特征变量的总数)的平方根进行分类。
3.2.1 分类系统的建立
依据“全国遥感监测土地利用/覆盖分类体系”,对研究区进行了两次野外实地调查,最终确定了湟水流域分类系统。中高山区(海拔>3200 m),气温较低,降水较多,植被覆盖好,主要以森林、草原分布为主,因此该区域的土地利用类型确定为林地、草地、水域及未利用土地;黄土丘陵区(2600~3200 m)以黄土源、梁、峁地貌类型为主,气候干燥,植被稀疏,因此该区域的土地利用类型确定为水浇地、坡耕地、林地、草地、水域、城乡工矿居民用地;河谷平原区(海拔<2600 m),地势平坦,土壤肥沃,该区域土地利用类型较为复杂,因而确定为水浇地、平原旱地、林地、草地、水域、城乡工矿居民用地以及未利用土地。
3.2.2 样本数据的采集
样本数据的采集包括野外调研与Google earth选点2种形式。分别于2016年8月15日-9月20日和2017年8月8日-8月19日对整个研究区进行野外实地采样,2016年共采集样本点539个,采集照片4367张,2017年共采集样本点174个,采集照片1552张。样本选择根据各地理分区的地形特点分区选取,为了确保实地采样过程中在未涉及的区域同样有训练样本与验证样本的分布,因此训练样本以选择2016年部分野外采样点为主并利用Google Earth选取的样点作为补充,验证样本采用2016年与2017年部分野外验证点,同时为了保证验证样本分布均匀和数量充足,借助Google Earth选取部分验证点进行补充。湟水流域土地利用/土地覆被类型的训练样本与验证样本的空间分布如图3所示。
图3 湟水流域土地利用类型训练样本与验证样本空间分布
Fig. 3 Training and validation samples of land use types in the Huangshui basin
本文共选择训练样本699个,包括野外采样点400个,Google Earth选点299个,验证样本907个,包括野外采样点313个,Google Earth选点594个,保证样本均匀分布的同时反复调整训练样本使分类效果达到最佳状态。每种土地利用/土地覆被类型均按照各个地理分区特点分区选取,例如脑山区多以草地、林地覆盖为主,因此在选取训练样本时,较多选取草地、林地等地物类型,并保证样本分布均匀。验证样本的选取与训练样本选取的方法一致。表2为不同地理分区各土地利用/土地覆被类型的训练样本与验证样本空间分布统计情况。
表2 各地理分区训练样本与验证样本统计
Tab. 2 Statistics of training and validation samples from each geographical region
| 样本 | 地理分区 | 水浇地 | 旱地 | 林地 | 高覆盖度草地 | 中覆盖度草地 | 低覆盖 度草地 | 水域 | 城乡、工矿、居民用地 | 未利用 土地 | 合计 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 训练 样本 | 脑山区 浅山区 川水区 合计 | - | - | 37 | 43 | 21 | - | 17 | - | 31 | 149 | |
| 25 | 68 | 46 | 34 | 20 | - | 30 | 29 | - | 252 | |||
| 35 | 39 | 29 | 27 | 28 | 30 | 30 | 55 | 25 | 298 | |||
| 60 | 107 | 112 | 104 | 69 | 59 | 77 | 55 | 56 | 699 | |||
| 验证 样本 | 脑山区 | - | - | 50 | 72 | 29 | - | 28 | - | 36 | 215 | |
| 浅山区 | 30 | 80 | 61 | 40 | 35 | - | 25 | 40 | - | 311 | ||
| 川水区 | 50 | 49 | 40 | 35 | 35 | 42 | 35 | 65 | 30 | 381 | ||
| 合计 | 80 | 129 | 151 | 147 | 99 | 42 | 88 | 105 | 66 | 907 | ||
本文在特征参数选择时,除采用OLI影像数据外,为了提高分类精度,结合湟水流域地形、土地利用/土地覆被类型分布规律和实地考察情况等综合考虑,本文还使用了归一化植被指数、归一化建筑指数、改进的归一化差异水体指数、数字高程模型、灰度共生矩阵等参数,每种特征参数的含义及特点见表3。
表3 特征参数特点及分类意义
Tab. 3 Characteristic parameter characteristics and classification significance
| 特征参数 | 特征参数特点及意义 | |
|---|---|---|
| Landsat8OLI 多光谱2~7 波段 | 2-蓝波段 | 对水体穿透强,可获得更多水下信息;能够区分土壤和植被、分析土地利用结构变化。 |
| 3-绿波段 | 主要观测植被在绿波段中的反射峰值,这一波段位于叶绿素的两个吸收带之间,利用这一波段增强鉴别植被的能力 | |
| 4-红波段 | 该波段为叶绿素的主要吸收波段,能增强植被覆盖与无植被覆盖之间的反差,亦能增强同类植被的反差,反映不同植物叶绿素吸收,植物健康状况,用于区分植物种类与植物覆盖率 | |
| 5-近红外波段 | 对植被类别差异最敏感,可以区别植被类型;由于处于水体强吸收区,因此呈现的水体轮廓清晰,便于与其他地物的区分 | |
| 7-短波红外2 | 反映植物和土壤水分含量敏感,可以区别雪和云 | |
| 8-短波红外2 | 可用于区分主要岩石类型;处于水的强吸收带,在影像上该波段的水体呈黑色;对植物水分敏感 | |
| 指数信息 | NDVI | 归一化差值植被指数,也称为生物量指标变化,可使植被从水和土中分离出来,是植被生长及植被覆盖度最佳指示因子 |
| NDBI | 归一化建筑物指数,利用了不透水面的中红外波段反射率高于近红外反射率的规律,该指数有助于城乡、工矿与居住建设用地的提取 | |
| MNDWI | 改进归一化差值水体指数,用遥感影像特定的波段进行改进的归一化差值处理,以突显影像中的水体信息 | |
| 地形信息 | DEM | 数字高程模型,可以提取坡度与坡向,影响研究区土地利用/土地覆被类型分布格局 |
| 纹理信息 | 纹理特征 | 纹理信息以灰度共生矩阵为主,是一种通过研究灰度的空间相关特性来描述纹理的常用方法;可以反映图像灰度分布均匀程度和纹理粗细程度 |
针对脑山区、浅山区、川水区的地形特点分别选择合适的特征参数可以在提高分类精度的同时降低数据冗余对分类造成的影响,因此在分类过程中分别提取三个区域的特征变量:① 光谱特征变量;② 纹理特征变量;③ 地形特征变量;对光谱特征变量中的指数信息进行内部归一化处理,以排除光谱特征在数值和类型上的不同所产生的影响。由于研究区的遥感影像为夏季,夏季是整体研究区内地物种类最全、纹理特征最明显的季节,因此提取Landsat8(OLI)影像2~7波段的纹理信息,综合多信息构建特征参数集。特征参数提取具体内容见表4。
表4 各地理分区特征参数提取
Tab. 4 Characteristic parameters extracted for each geographical subregion
| 地理分区/m | 特征信息 | 特征参数 |
|---|---|---|
| 脑山区(>3200 ) | 光谱信息 地形信息 | B,G,R,NIR,SWIR1,SWIR2,NDVI 高程,坡度,坡向 |
| 浅山区(2600~3200 ) | 光谱信息 纹理信息 地形信息 | B,G,R,NIR,SWIR1,SWIR2,NDVI,NDBI,MNDWI 均值,方差,同质性,对比度,非相似性,熵,二阶矩,相关性高程,坡度,坡向 |
| 川水区(<2600 ) | 光谱信息 纹理信息 地形信息 | B,G,R,NIR,SWIR1,SWIR2,NDVI,NDBI,MNDWI,PCA1,PCA2 均值,方差,同质性,对比度,非相似性,熵,二阶矩,相关性,高程,坡度,坡向 |
EnMap-Box是德国一款基于ENVI/IDL二次开发的处理高光谱遥感数据的工具箱软件,该软件不仅提供了许多种机器学习算法进行遥感影像的分类,还可以对高光谱影像数据和室内室外的光谱进行可视化、回归等处理。本文使用EnMap-Box软件平台结合ENVI 5.3进行分类研究。
根据各地理分区的地表覆盖类型及空间分布特征,在Landsat8 OLI多光谱2-7波段数据的基础上叠加地形、指数和纹理信息,为脑山区、浅山区与川水区构建了多个特征集,并对各特征集的有效性进行精度评价与分析,选取各地理分区中最优的分类特征集。
4.1.1 脑山区最优分类特征集
在构建脑山区最佳分类特征集时,本文设计了四种分类方案,各分类方案的实现也按四种方案顺序依次进行:①利用RFC方法仅对6个多光谱波段进行分类;②在多光谱2-7波段上叠加归一化差值植被指数(NDVI)进行分类;③在多光谱2-7波段上叠加坡度与坡向进行分类,由于该区域山区面积较大,且坡度相对较大,通过DEM生成坡度与坡向图,可以将分布于山体阴坡的林地与阳坡的草地进行区分;④将第2种方案与第3种方案结合起来进行分类,并对分类结果依次进行精度评价,结果如表5所示。
表5 脑山区分类特征集的样本分类精度评价
Tab. 5 Accuracles assessment of sample classification from classification feature sets in middle-high mountain area (%)
| 土地利用类型 | 6MS | 6MS+NDVI | 6MS+DEM | 6MS+DEM+NDVI | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 制图精度 | 用户精度 | 制图精度 | 用户精度 | 制图精度 | 用户精度 | 制图精度 | 用户精度 | ||||
| 林地 | 84.62 | 97.06 | 84.62 | 97.06 | 85.71 | 93.33 | 85.71 | 95.45 | |||
| 高草地 | 94.07 | 86.72 | 95.76 | 86.92 | 92.65 | 88.73 | 94.12 | 88.89 | |||
| 中草地 | 85.71 | 87.50 | 85.71 | 87.50 | 96.30 | 83.87 | 96.30 | 83.87 | |||
| 水域 | 92.73 | 94.44 | 90.91 | 94.34 | 92.31 | 94.70 | 92.31 | 97.70 | |||
| 未利用土地 | 93.48 | 91.49 | 93.48 | 91.49 | 88.46 | 92.00 | 88.46 | 92.00 | |||
| 总体精度 | 90.46 | 90.75 | 90.82 | 91.33 | |||||||
| Kappa系数 | 0.876 | 0.879 | 0.880 | 0.886 | |||||||
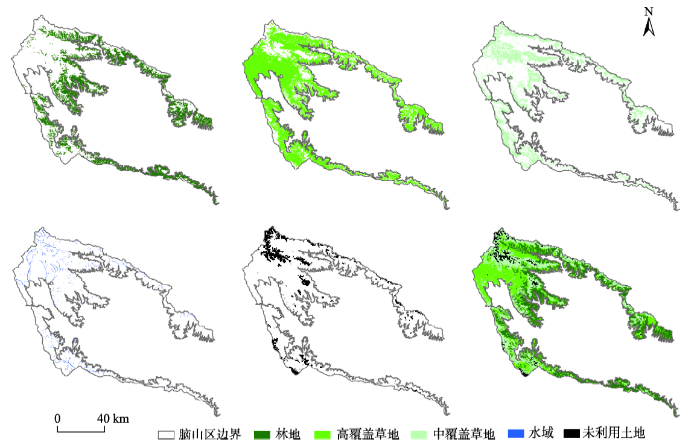
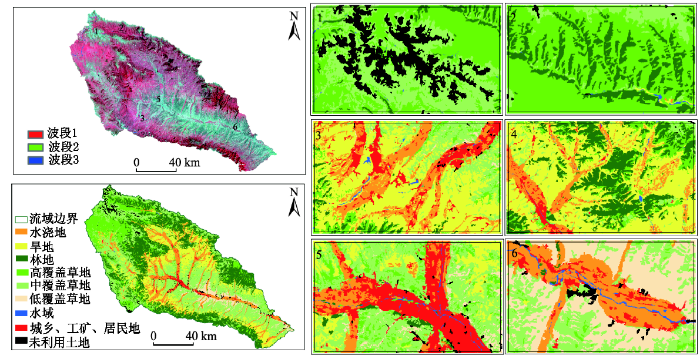
表5表明利用6个光谱波段的总体分类精度为90.46%,Kappa系数为0.876;在此基础上,增加NDVI指数,即6MS+NDVI其总体分类精度为90.75%,Kappa系数为0.879;进一步6MS+SL+AS其总体分类精度为90.82%,Kappa系数为0.880;6MS+SL+AS+NDVI其总体分类精度为91.33%,Kappa系数为0.886。分析表明采用6MS+SL+AS+NDVI分类精度最高。在脑山区,高覆盖草地容易与林地混分,可以看出6MS+SL+AS+NDVI作为脑山区最优分类特征集,不仅提高了总体的分类精度,还可以更好地识别脑山区中的地物信息,为浅山区与川水区的分类工作奠定了一定的基础。由于篇幅有限,仅将最优特征集土地利用信息提取结果显示(图4)。
图4 脑山区最优特征集6MS+SL+AS+NDVI分类结果
Fig. 4 The classification results from optimal feature set 6MS+SL+AS+NDVI in the middle-high area
4.1.2 浅山区最优分类特征集
该区域为黄土丘陵区,考虑该区域的地形特点,设计了3种分类方案,即多光谱波段+地形信息、多光谱波段+地形信息+指数信息以及多光谱波段+地形信息+指数信息+纹理信息。利用RFC方法,分别进行分类并用验证样本对分类结果进行精度评价,结果如表6所示。采用6MS+SL+AS进行分类,其总体分类精度为91.54%,Kappa系数为0.895;6MS+SL+AS+NDVI其总体分类精度为91.91%,Kappa系数为0.9;6MS+SL+AS+OIF+TXT总体分类精度为92.09%,Kappa系数为0.902。分析表明浅山区采用上述3种分类方案进行分类,总体分类精度均较高,并且采用的6MS+SL+AS+OIF+TXT分类精度最高(图5)。
表6 浅山区分类特征集的样本分类精度评价
Tab. 6 Accuracles assessment of sample classification from classification feature sets in the loess hilly area (%)
| 土地利用类型 | 6MS+SL+AS | 6MS+SL+AS+NDVI | 6MS+SL+AS +OIF+TXT | |||||
|---|---|---|---|---|---|---|---|---|
| 制图精度 | 用户精度 | 制图精度 | 用户精度 | 制图精度 | 用户精度 | |||
| 水浇地 | 90.91 | 95.00 | 90.91 | 95.24 | 90.91 | 95.24 | ||
| 旱地 | 94.74 | 88.34 | 94.74 | 91.14 | 94.74 | 90.57 | ||
| 林地 | 91.78 | 97.10 | 92.47 | 96.43 | 92.47 | 96.43 | ||
| 高草地 | 88.46 | 92.00 | 88.46 | 90.20 | 94.23 | 96.08 | ||
| 中草地 | 94.83 | 85.94 | 97.10 | 84.06 | 96.55 | 90.32 | ||
| 水域 | 88.89 | 94.12 | 88.89 | 94.12 | 91.67 | 80.49 | ||
| 城乡工矿居民用地 | 83.93 | 85.45 | 80.36 | 90.00 | 78.57 | 89.80 | ||
| 总体精度 | 91.54 | 91.91 | 92.09 | |||||
| Kappa系数 | 0.895 | 0.900 | 0.902 | |||||
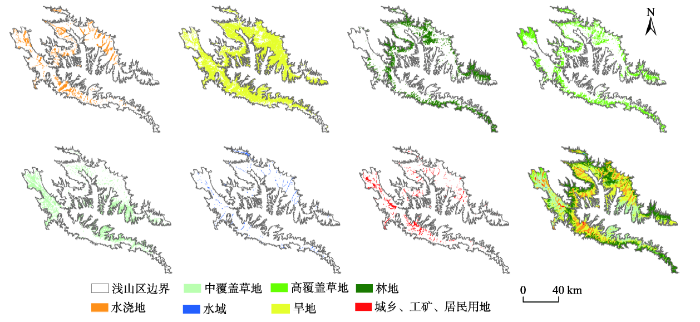
图5 浅山区最优特征集6MS+SL+AS+OIF+TXT分类结果
Tab. 5 The classification results from the optimal feature sets in the loess hilly area
浅山区以大面积耕地为主,通过地形信息可以很好地提取水浇地与旱地,二者的制图精度分别达到了90.91%与94.74%,通过叠加NDVI区分草地与林地,林地的制图精度提高了0.69%,中覆盖草地的制图精度提高了2.27%。通过叠加纹理信息、NDBI以及改进归一化差异水体信息使得水域的制图精度提高了2.78%,并且改善了整体的分类效果。因此,通过分类精度的对比,选用6MS+SL+AS+OIF+TXT作为浅山区最优分类特征集。
4.1.3 川水区最优特征集
构建川水区最优分类特征集的方案与浅山区的分类方案步骤相同:①采用6MS+SL+AS进行分类其总体分类精度为87.63%,Kappa系数为0.857;②采用6MS+SL+AS+NDVI进行分类,其总体分类精度为87.63%,Kappa系数为0.857;③采用6MS+SL+AS+OIF+TXT进行分类,其总体分类精度为87.85%,Kappa系数为0.859。分析表明上述3种分类方案中,6MS+SL+AS+OIF+TXT为最优分类方案,分类结果见表7。
表7 川水区分类特征集的样本分类精度评价
Tab. 7 Accuracles assessment of sample classification from classification feature sets in the valley plain area
| 土地利用类型 | 6MS+SL+AS | 6MS+SL+AS+NDVI | 6MS+SL+AS +OIF+TXT | |||||
|---|---|---|---|---|---|---|---|---|
| 制图精度/% | 用户精度/% | 制图精度/% | 用户精度/% | 制图精度/% | 用户精度/% | |||
| 水浇地 | 88.64 | 87.64 | 88.64 | 89.66 | 92.05 | 94.19 | ||
| 旱地 | 94.94 | 91.18 | 95.45 | 90.00 | 98.48 | 86.67 | ||
| 林地 | 72.17 | 73.16 | 72.17 | 76.67 | 77.83 | 78.75 | ||
| 高草地 | 75.00 | 73.18 | 75.00 | 78.18 | 75.00 | 73.75 | ||
| 中草地 | 84.44 | 95.00 | 84.44 | 95.00 | 93.33 | 90.00 | ||
| 低草地 | 94.83 | 84.62 | 94.83 | 82.09 | 89.66 | 77.61 | ||
| 水域 | 94.70 | 98.08 | 94.70 | 98.08 | 94.70 | 92.73 | ||
| 城乡工矿居民用地 | 95.45 | 87.50 | 94.32 | 90.22 | 90.91 | 86.96 | ||
| 未利用土地 | 76.67 | 80.95 | 73.33 | 76.19 | 70.00 | 75.00 | ||
| 总体精度/% | 87.63 | 87.63 | 87.85 | |||||
| Kappa系数 | 0.857 | 0.857 | 0.859 | |||||
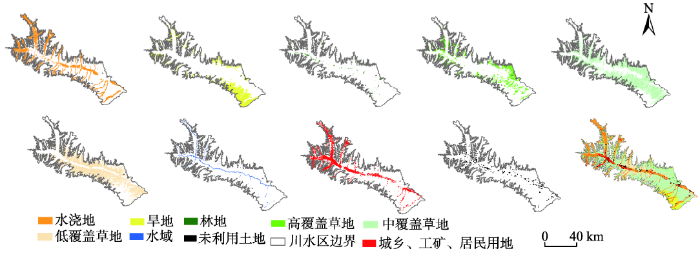
川水区土地类型复杂多样,从图6分类结果可以看出该区域6MS+SL+AS+OIF+TXT模型分类精度最高,因此在川水区可用其作为最优分类特征集。该分类方案精度较高的原因是水浇地与旱地需要坡度、坡向区分与提取,植被的区分需要NDVI的辅助,水体通过改进归一化差异水体信息提取,NDBI可以帮助提高城乡居住用地的分类精度,叠加纹理信息可以改善整体的分类效果,使得水浇地、旱地、林地、中草地的制图精度分别提高了3.41%、3.03%、5.66%、8.89%。
图6 川水区最优特征集6MS+SL+AS +OIF+TXT分类结果
Fig.6 The classification results from the optimal feature set 6MS+SL+AS+OIF+TXT in the valley plain area
为探索复杂地形区域土地利用类型信息提取效果更佳的方法,本文通过对多光谱2-7波段计算生成的8种纹理进行了分类实验,并对实验结果进行了检验,结果表明,方差纹理的分类精度最高。进一步在浅山区与川水区选取方差纹理进行优化选择纹理特征,脑山区土地利用类型相对单一在此不做研究。
4.2.1 浅山区优化选择纹理特征
在浅山区以多光谱2-7波段、地形信息、指数信息为基础,在其上分别增加8种纹理信息与方差纹理特征进行实验并对分类结果进行了检验,结果见表8。
表8 浅山区优化选择纹理特征分类精度评价
Tab. 8 Accuracles assessment of classification from optimized selection of texture feature in the loess hilly area
| 土地利用类型 | 6MS+DEM+NDVI+TXT(8) | 6MS+DEM+NDVI +TXT(var) | |||
|---|---|---|---|---|---|
| 制图精度/% | 用户精度/% | 制图精度/% | 用户精度/% | ||
| 水浇地 | 90.91 | 95.24 | 90.91 | 97.56 | |
| 旱地 | 94.74 | 89.44 | 94.74 | 91.14 | |
| 林地 | 92.47 | 95.74 | 94.52 | 97.18 | |
| 高草地 | 90.38 | 97.92 | 94.23 | 98.00 | |
| 中草地 | 98.28 | 90.48 | 96.55 | 87.50 | |
| 水域 | 91.67 | 80.49 | 91.67 | 89.19 | |
| 城乡工矿居民用地 | 76.79 | 89.58 | 78.57 | 84.62 | |
| 总体精度/% | 91.73 | 91.54 | |||
| Kappa系数 | 0.898 | 0.895 | |||
表8为采用6MS+SL+AS+NDVI+TXT(8)和6MS+SL+AS+NDVI+TXT(Var)分类方案的浅山区野外验证点的精度评价结果。可以看出,采用前者其总体分类精度为91.73%,Kappa系数为0.898;采用后者其总体分类精度为91.54%,Kappa系数为0.895。分析表明:当仅加入方差纹理特征时,林地、高覆盖草地、城乡工矿居民用地的制图精度分别比加入8种纹理特征的精度提高了2.05%、3.85%、1.78%,表明方差纹理特征可以有效的改善上述3类分类精度。
4.2.2 川水区优化选择纹理特征
在川水区优化选择特征组合时,设计了4套方案进行实验,首先采用6MS+SL+AS+NDVI+TXT(8)和6MS+SL+AS+NDVI +TXT(Var)分类方案,即加入8种类型纹理特征与仅加入方差纹理特征进行对比;其次采用了6MS+TXT(Var)+PCA1和6MS+TXT(Var)+PCA2对比2种主成分信息的分类结果见表9。
表9 川水区优化选择纹理特征分类精度评价
Tab. 9 Accuracles assessment of classification from optimized selection of texture feature in the valley plain area
| 土地利用类型 | 6MS+DEM+NDVI+TXT(8) | 6MS+DEM+NDVI +TXT(var) | 6MS+TXT(Var)+PCA1 | 6MS+TXT(var)+PCA2 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 制图精度/% | 用户精度/% | 制图精度/% | 用户精度/% | 制图精度/% | 用户精度/% | 制图精度/% | 用户精度/% | ||||
| 水浇地 | 90.91 | 96.39 | 88.64 | 88.65 | 90.59 | 86.52 | 90.59 | 86.52 | |||
| 旱地 | 96.97 | 81.01 | 95.45 | 88.73 | 84.29 | 90.77 | 84.29 | 90.77 | |||
| 林地 | 77.83 | 74.71 | 78.17 | 70.59 | 70.00 | 80.00 | 70.00 | 71.30 | |||
| 高草地 | 75.00 | 85.00 | 80.00 | 94.12 | 70.77 | 88.89 | 70.77 | 80.00 | |||
| 中草地 | 91.11 | 88.70 | 93.33 | 95.45 | 85.45 | 87.04 | 83.64 | 90.20 | |||
| 低草地 | 89.66 | 76.47 | 89.66 | 80.00 | 76.19 | 73.85 | 77.78 | 75.38 | |||
| 水域 | 92.30 | 92.73 | 94.70 | 89.47 | 98.08 | 78.46 | 70.00 | 77.61 | |||
| 城乡用地 | 89.77 | 86.81 | 92.05 | 88.04 | 87.95 | 73.00 | 87.95 | 70.19 | |||
| 未利用 | 76.67 | 70.00 | 78.00 | 73.33 | 82.50 | 75.79 | 75.00 | 72.22 | |||
| 总体精度/% | 86.78 | 87.42 | 80.44 | 80.85 | |||||||
| Kappa系数 | 0.847 | 0.854 | 0.774 | 0.779 | |||||||
采用6MS+SL+AS+NDVI+TXT(8),其总体分类精度为86.78%,Kappa系数为0.847;采用6MS+SL+AS+NDVI+TXT(Var),其总体分类精度为87.42%,Kappa系数为0.854;分析表明:叠加方差纹理的总体精度要高于加入8个类型纹理特征的0.64%,其中林地、高草地、中草地、水域、城乡工矿居民用地、未利用土地的制图精度分别提高了0.34%、5%、2.22%、2.4%、2.28%、1.33%。对比主成分信息的分类结果,采用6MS+TXT(Var)+PCA1模型的总体精度要低于6MS+TXT(Var)+PCA2模型的0.41%,相比之下第二主成分数据生成的方差纹理信息更为有效。
本文采用Landsat8OLI遥感影像为数据源,结合光谱、地形、纹理信息对复杂地形区湟水流域进行随机森林分区分类研究,并分析随机森林分类方法对复杂地形区土地利用类型分类的适用性。主要结论如下:① 本研究在脑山区(中高山区)、浅山区(黄土丘陵区)、川水区(河谷平原区)所构建的最优特征组合中综合模型分类效果最佳。脑山区结合光谱信息与地形信息的6MS+SL+AS+NDVI模型分类精度最优达到91.33%,其中NDVI与坡度、坡向的叠加对提取土地利用类型较为单一的脑山区植被信息发挥了重要的作用;在土地利用类型复杂的浅山区与川水区结合光谱、地形、纹理信息的6MS+SL+AS+OIF+TXT模型分类精度最优,其精度分别达到了92.09%和87.85%,将OIF指数信息加入到6MS+SL+AS模型中可以增强各地物之间的光谱差异,使得高覆盖草地、城乡工矿居民用地以及水体的分类精度显著提高,将纹理信息叠加至6MS+SL+AS+OIF模型分类中,能改善整体的分类精度。② 在土地利用类型复杂的浅山区与川水区分别选用6MS+SL+AS+NDVI+TXT(8)模型与6MS+SL+AS+NDVI+TXT(Var)模型进行优化选择纹理特征组合实验,实验结果表明选择优化后的方差纹理特征组合与加入8种纹理特征组合在精度上相差不是很明显,优化后的方差纹理特征组合6MS+SL+AS+NDVI+TXT(Var)模型在保持总体精度的同时可以较好地完成对湟水流域复杂地形区土地利用/土地覆被的分类。③ 本文选用Landsat8OLI中等分辨率卫星数据在中高山区、黄土丘陵区、河谷平原区进行随机森林分类,针对各个地理分区的特点选择最优的特征参数,经过分类结果的对比,得知3个区域的总体精度均达到80%以上,证明了随机森林方法对复杂地形区土地利用类型分类的适用性。
基于随机森林算法,选用光谱、地形和纹理特征,对湟水流域复杂地形区土地利用/土地覆被进行了分区分类研究(图7),根据分类精度评价结果表明,综合地形、光谱、纹理信息对湟水流域复杂地形区进行随机森林分类效果最佳,这一结论与马玥等[6]在基于随机森林算法的农耕区土地利用分类研究得出的结果一致。同时,对3个区域的精度评价结果进行对比发现,浅山区的总体精度要高于脑山区,与本研究相比,李金山[13]、贾伟等[14]用神经网络、决策树、支持向量机、面向对象等方法得出浅山区总体精度要低于脑山区,可能是因为本研究在随机森林方法中叠加了多信息的特征参数使得浅山区精度偏高。城乡工矿居民用地在遥感影像上的纹理特征较为明显,为了验证在浅山区与川水区选择纹理特征后的分类效果,选用了6MS+SL+AS+NDVI+TXT(8)和6MS+SL+AS+NDVI+TXT(Var)分类模型进行精度对比,发现浅山区与川水区加入8种纹理特征与仅加入方差纹理特征后的城乡工矿居民用地的制图精度后者比前者相对提高,但对最后分类的总体精度影响不是十分明显,经过仅选择方差纹理优化后的随机森林算法依然可以保持总体精度,这一结论与田绍鸿等[8]方法得出的结果相一致。
图7 基于随机森林方法的湟水流域土地利用信息提取结果
Fig. 7 Land use information extraction results in the Huangshui basin based on random forest method
本研究针对目标区域地貌类型复杂,土地利用类型多样等特点进行湟水流域土地利用/土地覆被分类,探索随机森林方法对复杂地形山区的适应性,对各个地理分区复杂地形下遥感影像土地利用信息提取准确性的提高以及及时有效地检测湟水流域地表变化,更新相关的地理信息具有重要意义。研究结果可为研究区湟水流域土地利用状况的更新、区域可持续发展提供决策支持。但本研究仍存在一定的不足,在每个地理分区选取相适宜的特征参数时考虑到湟水流域地形的复杂以及各地理分区的特点,但并未进一步定量地确定各地理分区生成树的数目,这将是本研究今后进一步的工作,另外随机森林算法虽然有较高的分类精度,利用特征参数及随机森林算法对不同时相及长时间序列遥感影像数据进行信息提取并获得较高的分类精度将是今后主要的研究工作。
The authors have declared that no competing interests exist.
| [1] |
基于混合像元分解决策树的土地利用/覆被分类研究 [D].Research on land use/land cover classification based on decision tree of mixed pixel decomposition [D]. |
| [2] |
基于神经网络的区域生态环境分类方法研究 [J].https://doi.org/10.3969/j.issn.1672-0504.2004.02.023 URL [本文引用: 1] 摘要
如何利用智能化信息提取技术,进行区域生态环境自动分类,一直是一种前沿性研究。该文在分析研究区自然景观特征的基础上,总结了影响区域生态环境的建模要素,基于神经网络技术,并根据生态环境的遥感探测机理,利用TM卫星遥感数据中的可见光、热红外、植被指数(NDVI)以及DEM数据,建立了基于BP神经网络的区域生态环境信息自动提取模型,形成了一种新的生态环境分类方法,其分类结果与实际情况完全一致。
Regional ecological environment classification methods based on neural networks [J].https://doi.org/10.3969/j.issn.1672-0504.2004.02.023 URL [本文引用: 1] 摘要
如何利用智能化信息提取技术,进行区域生态环境自动分类,一直是一种前沿性研究。该文在分析研究区自然景观特征的基础上,总结了影响区域生态环境的建模要素,基于神经网络技术,并根据生态环境的遥感探测机理,利用TM卫星遥感数据中的可见光、热红外、植被指数(NDVI)以及DEM数据,建立了基于BP神经网络的区域生态环境信息自动提取模型,形成了一种新的生态环境分类方法,其分类结果与实际情况完全一致。
|
| [3] |
遥感土地覆被分类的空间尺度响应研究 [J].
不同空间分辨率遥感影像对区域土地覆被类型识别精度的影响是目前土地资源遥感研究中的热点议题。本文基于准同步的卫星传感器影像,以福建省长汀县河田盆地为研究区,结合野外调查的实验样本,依次采用最大似然法(MLC)、支持向量机(SVM)和人工神经网络(ANN)3种分类器,分析土地覆被分类结果在中高空间尺度序列(1-50 m)下的变化响应特征。结果表明:不同空间尺度下的地物分类结果存在显著差异(P〈0.05),其中总分类精度和Kappa系数均随影像分辨率的降低而先升高后降低,并于4 m分辨率处达到峰值,该结果与各类地物光谱反射率的空间尺度变化特征密切相关;而不同分类器对各空间尺度影像分类结果的影响程度差异较大(P〈0.05),其中SVM的分类精度最优,MLC次之,ANN的结果较差。此外,伴随影像空间分辨率的降低,不同土地覆被类型面积提取结果的变化规律不同,导致同类地物在不同空间尺度下的提取结果出现较大差异,表明在使用多源分辨率遥感数据进行土地监测等相关研究时,其伴随的结果误差不容忽视。
Research on spatial scale response of remote sensing land cover classification [J].
不同空间分辨率遥感影像对区域土地覆被类型识别精度的影响是目前土地资源遥感研究中的热点议题。本文基于准同步的卫星传感器影像,以福建省长汀县河田盆地为研究区,结合野外调查的实验样本,依次采用最大似然法(MLC)、支持向量机(SVM)和人工神经网络(ANN)3种分类器,分析土地覆被分类结果在中高空间尺度序列(1-50 m)下的变化响应特征。结果表明:不同空间尺度下的地物分类结果存在显著差异(P〈0.05),其中总分类精度和Kappa系数均随影像分辨率的降低而先升高后降低,并于4 m分辨率处达到峰值,该结果与各类地物光谱反射率的空间尺度变化特征密切相关;而不同分类器对各空间尺度影像分类结果的影响程度差异较大(P〈0.05),其中SVM的分类精度最优,MLC次之,ANN的结果较差。此外,伴随影像空间分辨率的降低,不同土地覆被类型面积提取结果的变化规律不同,导致同类地物在不同空间尺度下的提取结果出现较大差异,表明在使用多源分辨率遥感数据进行土地监测等相关研究时,其伴随的结果误差不容忽视。
|
| [4] |
基于决策树的多角度遥感影像分类 [J].https://doi.org/10.3724/SP.J.1047.2016.00416 URL Magsci [本文引用: 1] 摘要
<p>快速准确地获取土地利用/覆被信息是遥感领域研究的一个热点课题.本文用5种决策树分类器及MISR多角度数据,对塔里木河下游地区进行土地覆被分类研究.通过对不同波段和观测角数据组合形成的6个数据集进行分类比较发现:(1)无论使用哪种分类器,相比于天底角观测方式,多角度观测都能获得更高的分类精度,特别是能显著提高灌木,林地和草地类型的分类精度,说明多角度观测能有效地反映地物的反射异质性信息,更好地区分地物.(2)与MLC分类法相比,决策树算法的分类精度更高,特别是随机森林和C 5.0方法最为突出,说明决策树的分类能力要优于MLC法.使用多角度数据集时,这种差别更明显,说明决策树能更有效地利用多角度信息.(3)4种决策树算法(J48,Random Forest,LMT,C 5.0)使用近红外波段的分类效果好于使用红光波段的分类效果,说明近红外波段能提供更多的地物反射异质性信息.</p>
Classification of multi-angle remote sensing images based on decision tree [J].https://doi.org/10.3724/SP.J.1047.2016.00416 URL Magsci [本文引用: 1] 摘要
<p>快速准确地获取土地利用/覆被信息是遥感领域研究的一个热点课题.本文用5种决策树分类器及MISR多角度数据,对塔里木河下游地区进行土地覆被分类研究.通过对不同波段和观测角数据组合形成的6个数据集进行分类比较发现:(1)无论使用哪种分类器,相比于天底角观测方式,多角度观测都能获得更高的分类精度,特别是能显著提高灌木,林地和草地类型的分类精度,说明多角度观测能有效地反映地物的反射异质性信息,更好地区分地物.(2)与MLC分类法相比,决策树算法的分类精度更高,特别是随机森林和C 5.0方法最为突出,说明决策树的分类能力要优于MLC法.使用多角度数据集时,这种差别更明显,说明决策树能更有效地利用多角度信息.(3)4种决策树算法(J48,Random Forest,LMT,C 5.0)使用近红外波段的分类效果好于使用红光波段的分类效果,说明近红外波段能提供更多的地物反射异质性信息.</p>
|
| [5] |
Random forests for land cover classification [C]// |
| [6] |
Evaluation of Random Forest and Adaboost tree-based ensemble classification and spectral band selection for ecotope mapping using airborne hyperspectral imagery [J].https://doi.org/10.1016/j.rse.2008.02.011 URL [本文引用: 2] 摘要
Detailed land use/land cover classification at ecotope level is important for environmental evaluation. In this study, we investigate the possibility of using airborne hyperspectral imagery for the classification of ecotopes. In particular, we assess two tree-based ensemble classification algorithms: Adaboost and Random Forest, based on standard classification accuracy, training time and classification stability. Our results show that Adaboost and Random Forest attain almost the same overall accuracy (close to 70%) with less than 1% difference, and both outperform a neural network classifier (63.7%). Random Forest, however, is faster in training and more stable. Both ensemble classifiers are considered effective in dealing with hyperspectral data. Furthermore, two feature selection methods, the out-of-bag strategy and a wrapper approach feature subset selection using the best-first search method are applied. A majority of bands chosen by both methods concentrate between 1.4 and 1.8 m at the early shortwave infrared region. Our band subset analyses also include the 22 optimal bands between 0.4 and 2.5 m suggested in Thenkabail et al. [Thenkabail, P.S., Enclona, E.A., Ashton, M.S., and Van Der Meer, B. (2004). Accuracy assessments of hyperspectral waveband performance for vegetation analysis applications. Remote Sensing of Environment, 91, 354 376.] due to similarity of the target classes. All of the three band subsets considered in this study work well with both classifiers as in most cases the overall accuracy dropped only by less than 1%. A subset of 53 bands is created by combining all feature subsets and comparing to using the entire set the overall accuracy is the same with Adaboost, and with Random Forest, a 0.2% improvement. The strategy to use a basket of band selection methods works better. Ecotopes belonging to the tree classes are in general classified better than the grass classes. Small adaptations of the classification scheme are recommended to improve the applicability of remote sensing method for detailed ecotope mapping.
|
| [7] |
Classifier ensembles for land cover mapping using multitemporal SAR imagery [J].https://doi.org/10.1016/j.isprsjprs.2009.01.003 URL [本文引用: 1] 摘要
SAR data are almost independent from weather conditions, and thus are well suited for mapping of seasonally changing variables such as land cover. In regard to recent and upcoming missions, multitemporal and multi-frequency approaches become even more attractive. In the present study, classifier ensembles (i.e., boosted decision tree and random forests) are applied to multi-temporal C-band SAR data, from different study sites and years. A detailed accuracy assessment shows that classifier ensembles, in particularly random forests, outperform standard approaches like a single decision tree and a conventional maximum likelihood classifier by more than 10% independently from the site and year. They reach up to almost 84% of overall accuracy in rural areas with large plots. Visual interpretation confirms the statistical accuracy assessment and reveals that also typical random noise is considerably reduced. In addition the results demonstrate that random forests are less sensitive to the number of training samples and perform well even with only a small number. Random forests are computationally highly efficient and are hence considered very well suited for land cover classifications of future multifrequency and multitemporal stacks of SAR imagery.
|
| [8] |
采用随机森林法的天绘数据干旱区城市土地覆盖分类 [J].https://doi.org/10.6046/gtzyyg.2016.01.07 URL Magsci [本文引用: 3] 摘要
<p>基于天绘一号(TH-1,或称MS-1)卫星多光谱数据,采用随机森林分类方法(random forests classification,RFC)对位于中亚干旱区的我国新疆维吾尔族自治区阿勒泰地区北屯市及周边区域的土地覆盖进行了分类研究。针对北屯市不透水层与裸土混杂的情况,将纹理特征与植被信息构建最优组合,建立有效的RFC分类器,提高对易混淆土地覆盖类型的分类识别精度。结果表明,采用RFC的分类精度高于最大似然法分类结果,总体分类精度提高了近10%。经过优化选择的特征组合在对干旱区中小城市土地覆盖进行分类时表现良好,能得到较高精度的分类结果,可满足新疆中小城市发展规划对土地覆盖信息的需求。</p>
Classification of urban land cover in arid region using sky-painted data of random forest method [J].https://doi.org/10.6046/gtzyyg.2016.01.07 URL Magsci [本文引用: 3] 摘要
<p>基于天绘一号(TH-1,或称MS-1)卫星多光谱数据,采用随机森林分类方法(random forests classification,RFC)对位于中亚干旱区的我国新疆维吾尔族自治区阿勒泰地区北屯市及周边区域的土地覆盖进行了分类研究。针对北屯市不透水层与裸土混杂的情况,将纹理特征与植被信息构建最优组合,建立有效的RFC分类器,提高对易混淆土地覆盖类型的分类识别精度。结果表明,采用RFC的分类精度高于最大似然法分类结果,总体分类精度提高了近10%。经过优化选择的特征组合在对干旱区中小城市土地覆盖进行分类时表现良好,能得到较高精度的分类结果,可满足新疆中小城市发展规划对土地覆盖信息的需求。</p>
|
| [9] |
基于随机森林算法的农耕区土地利用分类研究 [J].https://doi.org/10.6041/j.issn.1000-1298.2016.01.040 URL [本文引用: 1] 摘要
基于随机森林算法,采用多季节、多时相光谱信息、纹理信息和地形信息进行分类研究,选出最佳分类方案对农耕区土地利用信息进行提取,并利用随机森林算法对所有特征变量进行降维,将降维后的变量分别用于随机森林、支持向量机和最大似然分类法,分析不同分类方法对农耕区土地利用类型提取的适用性。研究结果表明:基于随机森林算法的多源信息综合分类方案进行土地利用信息提取效果最佳,总体精度85.54%,Kappa系数0.835 9;利用随机森林算法进行特征选择可以在有效降低数据维度的同时保证分类精度;3种分类方法中,随机森林算法总体分类精度81.08%,分别较支持向量机和最大似然法高9.46%和5.27%。利用随机森林分类法结合多源信息能够有效对农耕区土地利用类型进行分类,为土地类型的划分提供了快捷可行的方法。
Land use classification in agricultural land based on random forest algorithm [J].https://doi.org/10.6041/j.issn.1000-1298.2016.01.040 URL [本文引用: 1] 摘要
基于随机森林算法,采用多季节、多时相光谱信息、纹理信息和地形信息进行分类研究,选出最佳分类方案对农耕区土地利用信息进行提取,并利用随机森林算法对所有特征变量进行降维,将降维后的变量分别用于随机森林、支持向量机和最大似然分类法,分析不同分类方法对农耕区土地利用类型提取的适用性。研究结果表明:基于随机森林算法的多源信息综合分类方案进行土地利用信息提取效果最佳,总体精度85.54%,Kappa系数0.835 9;利用随机森林算法进行特征选择可以在有效降低数据维度的同时保证分类精度;3种分类方法中,随机森林算法总体分类精度81.08%,分别较支持向量机和最大似然法高9.46%和5.27%。利用随机森林分类法结合多源信息能够有效对农耕区土地利用类型进行分类,为土地类型的划分提供了快捷可行的方法。
|
| [10] |
随机森林算法在干旱区土地利用遥感分类中的应用研究 [J].https://doi.org/10.13880/j.cnki.65-1174/n.2017.01.016 URL [本文引用: 1] 摘要
为了验证随机森林算法在干旱区土地利用遥感分类中的效果,本文采用随机森林算法,结合Landsat8遥感影像以及DEM、NDVI等辅助数据,解译了干旱区典型流域玛纳斯河流域的土地利用图。分析结果表明:(1)分析决策树数量(k)和分类变量数量(m)对分类精度具有很大影响。通过优化2个参数得到最优随机森林模型,当k取103、m取6时,模型分类精度可达95%;(2)通过土地利用分类精度的影响因子分析发现,海拔高程和归一化植被指数对土地利用分类的影响程度比坡向的影响更大。(3)通过分类结果对比分析发现,应用随机森林算法分类的精度比用最大似然法的分类精度高9%,利用变量重要性筛选出的遥感波段构建优化随机森林模型,能有效降低遥感数据源数据量,而Kappa系数保持在0.97不变。随机森林算法可以在干旱区土地利用分类中广泛应用。
Application of random forest algorithm in remote sensing classification of land use in arid areas [J].https://doi.org/10.13880/j.cnki.65-1174/n.2017.01.016 URL [本文引用: 1] 摘要
为了验证随机森林算法在干旱区土地利用遥感分类中的效果,本文采用随机森林算法,结合Landsat8遥感影像以及DEM、NDVI等辅助数据,解译了干旱区典型流域玛纳斯河流域的土地利用图。分析结果表明:(1)分析决策树数量(k)和分类变量数量(m)对分类精度具有很大影响。通过优化2个参数得到最优随机森林模型,当k取103、m取6时,模型分类精度可达95%;(2)通过土地利用分类精度的影响因子分析发现,海拔高程和归一化植被指数对土地利用分类的影响程度比坡向的影响更大。(3)通过分类结果对比分析发现,应用随机森林算法分类的精度比用最大似然法的分类精度高9%,利用变量重要性筛选出的遥感波段构建优化随机森林模型,能有效降低遥感数据源数据量,而Kappa系数保持在0.97不变。随机森林算法可以在干旱区土地利用分类中广泛应用。
|
| [11] |
基于机器学习的湟水流域土地利用/土地覆被分类研究 [D].Research on land use/land cover classification based on machine learning in huangshui river basin [D]. |
| [12] |
青海高原东部农业区土地利用遥感分类制图 [J].https://doi.org/10.3969/j.issn.1002-6819.2012.16.035 URL Magsci [本文引用: 1] 摘要
为有效地监测复杂区域生态环境治理成效,该文以青藏高原与黄土高原过渡地带的青海高原东部农业区为例,研究大范围复杂地区土地利用遥感自动、快速提取方法。首先构建适于研究区土地利用变化分析的分类系统;其次,采用地理分区综合遥感分类法对青海高原东部农业区进行土地利用遥感分类制图。研究结果表明,上述方法适宜大范围复杂地区土地利用信息的有效提取,Kappa系数0.71,较未分区的分类结果高0.12。分类制图结果表明,研究区土地利用结构以农用地为主,其中>6°~25°的坡耕地占耕地总量的63.33%,应加大这部分坡耕地水土流失的防治。该研究为大范围复杂地区土地利用遥感信息提取提供了有效的方法,为青海高原东部农业区土地资源的科学管理与规划提供了参考。
Remote sensing classification mapping of land use in the eastern qinghai plateau agricultural region [J].https://doi.org/10.3969/j.issn.1002-6819.2012.16.035 URL Magsci [本文引用: 1] 摘要
为有效地监测复杂区域生态环境治理成效,该文以青藏高原与黄土高原过渡地带的青海高原东部农业区为例,研究大范围复杂地区土地利用遥感自动、快速提取方法。首先构建适于研究区土地利用变化分析的分类系统;其次,采用地理分区综合遥感分类法对青海高原东部农业区进行土地利用遥感分类制图。研究结果表明,上述方法适宜大范围复杂地区土地利用信息的有效提取,Kappa系数0.71,较未分区的分类结果高0.12。分类制图结果表明,研究区土地利用结构以农用地为主,其中>6°~25°的坡耕地占耕地总量的63.33%,应加大这部分坡耕地水土流失的防治。该研究为大范围复杂地区土地利用遥感信息提取提供了有效的方法,为青海高原东部农业区土地资源的科学管理与规划提供了参考。
|
| [13] |
湟水流域川水区、浅山区、脑山区和石山林区划分及特点 [J].https://doi.org/10.3969/j.issn.1006-7175.2012.02.007 URL [本文引用: 2] 摘要
湟水流域地处青藏高原和黄土高原过渡带,地形相对高差大,气温、降水、植被、土壤等随地形海拔高度的不同有明显的差异。依据地形、气候及农业生产特点的不同,划分为4种地貌单元,按当地习惯称为脑山区、浅山区、川水区和石山林区,4类迥然不同的气候区域,导致了不同的农业生态环境和社会经济发展背景。对川水区、浅山区、脑山区和石山林区的划分及特点进行了较为详尽的论述。
Division and characteristics of valley plains, loess hills, middle and high mountains and stone mountain forests in huangshui river basin [J].https://doi.org/10.3969/j.issn.1006-7175.2012.02.007 URL [本文引用: 2] 摘要
湟水流域地处青藏高原和黄土高原过渡带,地形相对高差大,气温、降水、植被、土壤等随地形海拔高度的不同有明显的差异。依据地形、气候及农业生产特点的不同,划分为4种地貌单元,按当地习惯称为脑山区、浅山区、川水区和石山林区,4类迥然不同的气候区域,导致了不同的农业生态环境和社会经济发展背景。对川水区、浅山区、脑山区和石山林区的划分及特点进行了较为详尽的论述。
|
| [14] |
复杂地形区土地利用/土地覆被分类研究——以湟水流域为例 [D].A study on land use/land cover changes in complex topographical areas: A case study of the Qinshui river basin [D]. |
| [15] |
面向对象方法的复杂地形区地表覆盖信息提取 [J].Surface cover information extraction of complex topographic areas by object-oriented method [J]. |
| [16] |
随机森林模型在分类与回归分析中的应用 [J].https://doi.org/10.7679/j.issn.2095-1353.2013.163 URL [本文引用: 1] 摘要
随机森林(random forest)模型是由Breiman和Cutler在2001年提出的一种基于分类树的算法。它通过对大量分类树的汇总提高了模型的预测精度,是取代神经网络等传统机器学习方法的新的模型。随机森林的运算速度很快,在处理大数据时表现优异。随机森林不需要顾虑一般回归分析面临的多元共线性的问题,不用做变量选择。现有的随机森林软件包给出了所有变量的重要性。另外,随机森林便于计算变量的非线性作用,而且可以体现变量间的交互作用(interaction)。它对离群值也不敏感。本文通过3个案例,分别介绍了随机森林在昆虫种类的判别分析、有无数据的分析(取代逻辑斯蒂回归)和回归分析上的应用。案例的数据格式和R语言代码可为研究随机森林在分类与回归分析中的应用提供参考。
Application of stochastic forest model in classification and regression analysis [J].https://doi.org/10.7679/j.issn.2095-1353.2013.163 URL [本文引用: 1] 摘要
随机森林(random forest)模型是由Breiman和Cutler在2001年提出的一种基于分类树的算法。它通过对大量分类树的汇总提高了模型的预测精度,是取代神经网络等传统机器学习方法的新的模型。随机森林的运算速度很快,在处理大数据时表现优异。随机森林不需要顾虑一般回归分析面临的多元共线性的问题,不用做变量选择。现有的随机森林软件包给出了所有变量的重要性。另外,随机森林便于计算变量的非线性作用,而且可以体现变量间的交互作用(interaction)。它对离群值也不敏感。本文通过3个案例,分别介绍了随机森林在昆虫种类的判别分析、有无数据的分析(取代逻辑斯蒂回归)和回归分析上的应用。案例的数据格式和R语言代码可为研究随机森林在分类与回归分析中的应用提供参考。
|
| [17] |
随机森林理论浅析 [J].Analysis of random forest theory [J]. |
| [18] |
On oblique random forests [C]// |
| [19] |
Effective mammogram classification based on center symmetric-LBP features in wavelet domain using random forests [J].https://doi.org/10.3233/THC-170851 URL PMID: 28582938 [本文引用: 1] 摘要
Abstract Mammogram classification is a crucial and challenging problem, because it helps in early diagnosis of breast cancer and supports radiologists in their decision to analyze similar mammograms out of a database by recognizing the classes of current mammograms. This paper proposes an effective method for classifying mammograms using random forests with wavelet based center-symmetric local binary pattern (WCS-LBP). To classify mammograms, multi-resolution CS-LBP texture characteristics from non-overlapping regions of the mammograms are captured. Further, we examine most relevant features using support vector machine-recursive feature elimination (SVM-RFE). Finally, we feed the selected features to decision trees and construct random forests which are an ensemble of random decision trees. Using wavelet based local CS-LBP features with random forest, we classify the test images into different categories having the maximum posterior probability. The proposed method shows the improved performance as compared with other variant features and state-of-art methods. The obtained performance measures are 97.3% accuracy, 97.3% precision, 97.2% recall, 97.2% F-measure and 94.1% Matthews correlation coefficient (MCC).
|
| [20] |
基于随机森林的大姚县TM遥感影像分类研究 [J].https://doi.org/10.3969/j.issn.1671-3168.2014.02.001 URL [本文引用: 1] 摘要
随机森林(Random Forest)是一种组合多棵决策树分类器的新的分类算法。以楚雄州大姚县为例,采用Landsat-TM数据,通过最大似然、支持向量机、随机森林3种分类器进行分类对比研究。结果表明,支持向量机和随机森林的分类精度明显优于最大似然法,两者分类精度相差不大;在分类时间上,最大似然法明显比随机森林和支持向量机快,支持向量机最慢。综合分析,随机森林算法表现更优,它在保证分类精度的前提下,也能保证一定的时间效率,更适宜实际生产应用。
Remote sensing image classification of dayao county based on random forest [J].https://doi.org/10.3969/j.issn.1671-3168.2014.02.001 URL [本文引用: 1] 摘要
随机森林(Random Forest)是一种组合多棵决策树分类器的新的分类算法。以楚雄州大姚县为例,采用Landsat-TM数据,通过最大似然、支持向量机、随机森林3种分类器进行分类对比研究。结果表明,支持向量机和随机森林的分类精度明显优于最大似然法,两者分类精度相差不大;在分类时间上,最大似然法明显比随机森林和支持向量机快,支持向量机最慢。综合分析,随机森林算法表现更优,它在保证分类精度的前提下,也能保证一定的时间效率,更适宜实际生产应用。
|
| [21] |
基于随机森林CA的东莞市多类土地利用变化模拟 [J].https://doi.org/10.3969/j.issn.1672-0504.2016.05.005 URL [本文引用: 1] 摘要
城市土地利用及其变化对城市环境有着重要影响。很多学者已经结合元胞自动机和机器学习算法对城市扩张进行了相关的模拟研究,但针对复杂的多类土地利用相互变化过程的研究仍然较少。该文提出了一种基于随机森林算法的多类元胞自动机(RFA-CA)模型,并将其用于模拟和预测复杂的多类土地利用变化。该模型使用随机森林算法提取元胞自动机的转换规则,并计算了各空间变量的重要性,在东莞市2000-2014年土地利用动态模拟结果中,Kappa系数和整体精度分别为0.73和84.7%。针对每一种土地利用类型,计算了影响东莞市土地利用变化的各空间变量的重要性,结果显示,交通、区位因素对东莞市土地利用变化格局的形成有重要影响。文中引入的POIs邻近因素反映了城市空间开发程度的高低,同样对多类土地利用格局的形成具有重要作用。
Simulation of multiple land use changes in dongguan city based on stochastic forest CA [J].https://doi.org/10.3969/j.issn.1672-0504.2016.05.005 URL [本文引用: 1] 摘要
城市土地利用及其变化对城市环境有着重要影响。很多学者已经结合元胞自动机和机器学习算法对城市扩张进行了相关的模拟研究,但针对复杂的多类土地利用相互变化过程的研究仍然较少。该文提出了一种基于随机森林算法的多类元胞自动机(RFA-CA)模型,并将其用于模拟和预测复杂的多类土地利用变化。该模型使用随机森林算法提取元胞自动机的转换规则,并计算了各空间变量的重要性,在东莞市2000-2014年土地利用动态模拟结果中,Kappa系数和整体精度分别为0.73和84.7%。针对每一种土地利用类型,计算了影响东莞市土地利用变化的各空间变量的重要性,结果显示,交通、区位因素对东莞市土地利用变化格局的形成有重要影响。文中引入的POIs邻近因素反映了城市空间开发程度的高低,同样对多类土地利用格局的形成具有重要作用。
|
| [22] |
基于随机森林算法的近地表气温遥感反演研究 [J].https://doi.org/10.3724/SP.J.1047.2017.00390 URL [本文引用: 1] 摘要
近地表气温是城市热环境的重要表征,是改变和影响城区气候的重要因素。为获得空间上连续的近地表气温,本文以北京市为研究区,利用Landsat5/TM数据计算分别得到地表温度、归一化植被指数、改进的归一化差异水体指数、地表反照率、不透水面盖度,并结合气象站点气温和高程作为输入参数建立随机森林模型反演近地表气温。结果表明,随机森林反演的近地表气温平均绝对误差(MAE)为0.80℃,均方根误差(RMSE)为1.06℃,与传统多元线性气温回归方法相比,平均绝对误差(MAE)和均方根误差(RMSE)分别提高0.06℃和0.09℃。研究表明,利用随机森林模型反演近地表气温是可行的,并且具有一定的优越性。此外,对随机森林模型的输入参数进行重要性分析,地表温度对气温反演模型的影响最大,其次为高程。
Research on remote sensing inversion of near-surface temperature based on stochastic forest algorithm [J].https://doi.org/10.3724/SP.J.1047.2017.00390 URL [本文引用: 1] 摘要
近地表气温是城市热环境的重要表征,是改变和影响城区气候的重要因素。为获得空间上连续的近地表气温,本文以北京市为研究区,利用Landsat5/TM数据计算分别得到地表温度、归一化植被指数、改进的归一化差异水体指数、地表反照率、不透水面盖度,并结合气象站点气温和高程作为输入参数建立随机森林模型反演近地表气温。结果表明,随机森林反演的近地表气温平均绝对误差(MAE)为0.80℃,均方根误差(RMSE)为1.06℃,与传统多元线性气温回归方法相比,平均绝对误差(MAE)和均方根误差(RMSE)分别提高0.06℃和0.09℃。研究表明,利用随机森林模型反演近地表气温是可行的,并且具有一定的优越性。此外,对随机森林模型的输入参数进行重要性分析,地表温度对气温反演模型的影响最大,其次为高程。
|
| [23] |
随机森林及其在遥感影像处理中应用研究 [D].Application of random forest and its application in remote sensing image processing [D]. |
| [24] |
A Random Forests classification method for urban land-use mapping integrating spatial metrics and texture analysis [J].https://doi.org/10.1080/01431161.2017.1395968 URL [本文引用: 1] 摘要
react-text: 380 At present, many approaches and models have been developed to perform spatially explicit simulations that mimic observed land use and land cover changes (LULC) for a given area. Calibration of such models is often performed using comparatively standard ‘off-the-shelf’ machine-learning algorithms that are not necessarily suited to perform effectively within the model’s implementation. This... /react-text react-text: 381 /react-text [Show full abstract]
|

/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}