程希萌 , 沈占锋, 邢廷炎
, 沈占锋, 邢廷炎
CHENG Ximeng, SHEN Zhanfeng, XING Tingyan
通讯作者:
收稿日期: 2015-10-27
修回日期: 2015-12-4
网络出版日期: 2016-06-10
版权声明: 2016 《地球信息科学学报》编辑部 《地球信息科学学报》编辑部 所有
基金资助:
作者简介:
作者简介:程希萌(1991-),男,硕士生,研究方向为空间数据挖掘。E-mail: cheng_ximeng@126.com
展开
摘要
在遥感图像分类过程中,进行合理的特征优选操作,将有助于提高分类器的分类效率及精度。本文以淮南地区资源三号卫星多光谱遥感影像数据为例,采用二值离散化、直方图法及F统计法3种计算方法实现mRMR(minimal-Redundancy-Maximal-Relevance)算法特征优选过程。根据3种方法所得到的特征优选结果及全部特征信息,分别采用C5.0决策树和K近邻2种分类器进行图像分类实验,并利用目视解译方法对不同方法组合的影像分类结果进行精度验证。实验结果表明,利用3种计算方法实现mRMR特征优选算法对不同分类器的影响程度不同:在分类效率方面,C5.0决策树分类器可提高36.84%,而K近邻分类器可提高72.05%;在分类精度方面,C5.0决策树分类器能保证分类精度大致不变,总体分类精度可提高0.60%,Kappa系数可提高0.80%,而K近邻分类器总体分类精度可提高4.34%,Kappa系数可提高7.90%。
关键词:
Abstract
Image classification is a popular research topic in the field of remote sensing. This technology has been widely used in environmental protection, military, urban planning, and other fields. Interfering by the massive feature information of remote sensing image, applying the reasonable feature selection approach in the progress of image classification becomes critical for improving the efficiency and accuracy of classification. This paper extracts the image feature data from the ZY3 satellite multispectral image of Huainan region, and studies the mRMR (minimal-Redundancy-Maximal-Relevance) feature selection method. This algorithm has a simple core principle and low requirement of data. The core problem of this algorithm is the computation of mutual information. The mRMR algorithm is initially applied in the field of bioscience, such as the gene expression analysis, and it is not widely used in the field of remote sensing. This research uses three methods (the binary discretization, histogram method and F-statistic) to realize the computation process of mRMR algorithm. And two classifiers (the C5.0 decision tree and k-nearest neighbour) are used for the classification based on three types of feature selection results and the total feature information. Moreover, the visual interpretation is used to verify the image classification results from these different methods. The study shows that the results produced by different mRMR computation processes are distinct regarding to different classifiers. In terms of efficiency, all methods can improve the efficiency of C5.0 and KNN. The classification efficiency is increased by 36.84% for C5.0 and by 72.05% for KNN. In terms of accuracy, all method can maintain the accuracy of C5.0 while improve the accuracy of KNN. The total classification accuracy and Kappa coefficient are increased for C5.0 by 0.60% and 0.80%, respectively. The total classification accuracy is increased by 4.34% and the Kappa coefficient is increased by 7.90% for KNN. In summary, the feature selection method based on the mRMR algorithm is effective in the procedure of multispectral image classification.
Keywords:
自20世纪后期以来,遥感技术作为一门新兴学科迅速发展[1],遥感图像分类技术作为遥感研究的关键技术之一,已被广泛应用于环境保护[2]、军事[3]、城市规划[4]等领域。在遥感图像分类过程中,依据全部特征进行分类会对分类效率与精度造成影响,因此需要从原始特征集中选择一些关键特征,在保证不减少分类相关信息的同时减少数据总量,以达到特征优选的目的[5]。目前,较常用的特征优选方法包括主成分分析(Principle Component Analysis,PCA)、独立成分分析(Independent Component Analysis,ICA)、流形学习等。主成分分析的基本思想是搜索方向矢量,使样本之间散度最大[6],其虽很好地考虑到特征之间的相互关系,但该方法对数据要求高,不适用于小样本的情况[7]。独立成分分析是从多元统计数据中寻找潜在成分的方法,与其他方法相比,其意义在于寻找满足统计独立和非高斯的成分,但其无法确定独立成分的顺序[8]。流形学习是一种非线性维数约简方法,能有效地探测非线性数据的内部结构,但其存在小样本问题以及噪声敏感问题[9]。这些特征优选方法均较为成熟,但也都存在一定局限性。
最小冗余最大相关(mRMR)算法[10]是一种基于互信息理论的特征优选方法,为解决这些局限性提供了契机。优选标准是使所选特征子集与类别之间的相关性最大,同时保证所选特征之间的冗余尽量小。mRMR算法原理较为简单,核心问题是对互信息的计算,其对数据要求低,具有较高的计算效率[11],目前主要应用于医药及生命科学领域[12]。在遥感图像分类研究领域,国内已有学者开始将mRMR算法应用于遥感图像分类[13-14],但其研究更多基于国外高光谱影像或具有高维特征信息的影像数据,对于常用国产卫星影像的研究较少。而且前人的研究更多侧重于证明mRMR算法的有效性以及将mRMR算法与其他方法相结合,并没有深入研究不同的计算方法对mRMR算法优选效果的影响,也没有深入研究mRMR特征优选对原理不同的分类器的优化效果差异。本文基于资源三号卫星多光谱数据,利用二值离散化、直方图法、F统计法3种计算方法实现mRMR优选过程,并基于优选结果利用C5.0决策树与K近邻2种分类器进行图像分类,通过对实验结果的分析,验证并比较不同方法对分类器的优化效果。
最小冗余最大相关(mRMR)算法是由Peng在2005年提出[10],其基本思想是利用信息论中的相关理论,以互信息量的大小作为衡量特征与特征、特征与类别标签间相关性的标准。
互信息(Mutual Information)表示2个随机变量之间的相关性[15]。基于互信息理论,Peng用特征子集中每一特征与类别标签的互信息均值表示相关性,同时用所选特征两两之间的互信息均值表示特征子集的冗余性。优选的最终目的是最大化特征子集与类别标签的相关性,同时最小化特征子集的冗余性。
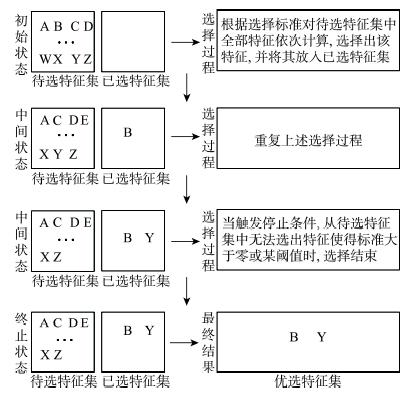
将特征子集与类别标签的相关性记为
根据式(1)的子集评价标准,特征选择方法采用渐进式搜索算法。假设特征全集为X,特征子集为S,类别标签为C,I表示互信息。当前已进行m-1次选择,选出了具有m-1个特征的特征子集Sm-1,将要进行第m次选择,则选择标准如式(2)所示。
在进行第m次选择时,在待选特征集
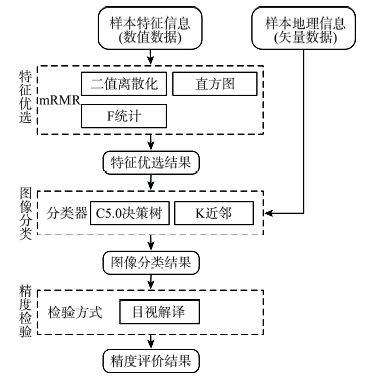
以样本特征信息以及样本地理信息为基础,将实验分为3部分,即特征优选、图像分类以及精度检验,实验流程图如图2所示。
2.2.1 特征优选
依据mRMR算法的计算特点以及所得特征数据的数据类型,本文分别采用二值离散化、直方图法、F统计法3种计算方法实现特征优选过程。这3种方法计算简便且理论成熟,对数据要求低,具有较强的通用性[10,12,16-17]。
(1)二值离散化
mRMR算法在计算互信息的过程中,需大量估计概率密度以及多元概率密度。针对上述问题,采用二值离散化方法(Binary Discretization,BD)[10],将每一样本特征值按式(3)归为两类,使概率估计更容易。设特征总数为M,样本总数为N,则第i个样本的第j个特征值xij经过二值离散化可表示为式(3)。
式中:
通过二值离散化,所有样本的特征值均变为1或-1。在估计概率密度时,可以采用该值样本个数与总体样本个数的比值进行估算,而对于联合概率密度的估算也可采取同样的计算方法。
(2)直方图法
直方图法(Histogram Method,HM)是概率分布的一种估计方法,对于每一个随机变量的取值,按照一定间距取若干个间隔点,将其值域划分为若干份,通过统计每2个间隔点间的样本个数,从而绘制频率分布直方图,达到概率分布近似的目的[16]。设特征总数为M,样本总数为N,对于第j个特征xj,确定其直方图间隔为hj,分隔区间数目为Kj,则其近似的概率密度函数为式(4)。
式中:vkj表示对于第j个特征xj,按照其直方图间隔hj进行划分,落入第k个区间中的样本数目;第k个区间的左右两间隔点分别用tk、tk+1表示。其中,间隔h通过式(5)的经验公式[16]来确定。
式中:
(3)F统计法
由于mRMR算法中互信息的计算较复杂,为此也可采用计算F统计量(F-statistic)以及皮尔逊相关系数来表示变量间的相关程度,代替互信息作为衡量相关性的标准[12]。因此,式(2)的渐进式搜索选择标准也有所变化,新的选择标准如式(6)所示。
式中:
假设对于全部样本共有K种类别标签,则F统计量的计算公式如式(7)所示[12,17]。
式中:k表示不同类别标签;
式中:
2.2.2 图像分类
本文采用C5.0决策树及K近邻2种比较普遍,且通用性较强的分类器[18]进行遥感图像分类实验。
(1) C5.0决策树
决策树(Decision Tree)的应用范围很广,其优点在于计算复杂度低,且分类过程利于理解,缺点在于可能出现过度匹配问题[19]。本文采用C5.0决策树,它是在C4.5决策树的基础上发展而来,比C4.5决策树更加高效和稳定[18]。决策树的构建过程是以特征集中的某一特征作为根结点,依据最大信息增益的标准,选择特征集中的剩余特征进行建树并对样本集进行划分。若某划分子集中的样本类别标签均相同或某类别标签占有较大比例,则无需继续划分,该子集即为决策树的叶子结点[20]。
(2) K近邻
K近邻方法(K-Nearest Neighbour,KNN)的基本思想是对任意待测样本对象进行分类时,计算其与全部训练样本数据的欧式距离,选择距离最短的前K个训练样本,按照这K个训练样本的类别标签出现次数,用出现最多的类别标签标记该待测样本。K近邻方法的优点在于对分类数据的要求较低,且对异常值不敏感,缺点在于计算复杂度高、空间复杂度高[19]。本文采用的K近邻方法,固定取K=5,即对于每一个待分类样本,选择与其欧式距离最短的5个训练样本数据进行分析。
2.2.3 精度检验
本文所采用的精度检验方式为目视解译,即基于图像分类结果,从全部样本中随机选取200个样本作为测试样本,通过目视解译的方式人工判别样本地物类型,并将其与分类结果进行对比,从而得出图像分类结果的精度评价。在精度检验过程中,以目视解译结果作为近似真实值难免会存在人为误差,但在难以进行实地考察以获得真实数据的前提下,目视解译作为较为准确且快速的地物类型判别方法,在遥感领域里应用广泛,且具有一定合理性。
研究区位于淮南市东北部的上窑镇。淮南市位于安徽省中北部地区(116º21′~117º11′E,32º32′~33º00′N),年平均气温为15 ℃,是中国安徽省以及华东地区重要的煤炭资源产地[21-22]。
本文实验所用数据为国产资源三号卫星多光谱遥感影像,数据获取时间为2013年3月18日,影像分辨率为5.8 m。图3为经辐射校正与几何校正后的上窑镇研究区的数据影像,其覆盖范围约为62 km2。
基于数据影像,利用人工勾画方式进行样本选取。由于研究区地物类型较为分明,为减少特征提取以及地物类型自身分辨难度对图像分类的影响,本文选择4种不同地物类型(建设用地、植被、水体、裸地)进行分类。影像分割方法采用均值漂移算法[23],分割对象总数为10 449,将分割后的结果与人工选取的样本进行匹配,共计得到1591个样本对象,其中建设用地、植被、水体、裸地4种地物类型的样本个数分别为236、722、246、387。对全部的分割对象进行特征提取,为更好地检验特征优选效果,共提取特征27个,包括光谱特征、几何特征、空间关系、纹理特征4种特征类型(表1)。
表1 特征信息
Tab. 1 Feature information
| 特征类型 | 特征名称 | 特征数目 |
|---|---|---|
| 光谱特征 | 第1-4波段均值、第1-4波段标准差、NDWI均值、NDWI标准差、NDVI均值、NDVI标准差 | 12 |
| 几何特征 | 长、宽、长宽比、像元数目、边长、形状指数、角点数目 | 7 |
| 空间关系 | 紧致度、主方向 | 2 |
| 纹理特征 | 同质性、对比度、相异性、角二阶矩、熵、相关性 | 6 |
经过数据准备阶段,得到研究区域的地物对象样本,并且针对每一个样本,获得了27个特征的数据信息。基于遥感特征数据,分别利用二值离散化(BD)、直方图法(HM)以及F统计法(F)3种方法实现mRMR算法的计算过程。利用3种计算方法所得mRMR算法特征优选结果如表2所示。
表2 mRMR算法特征优选结果
Tab. 2 The result of feature selection based on the mRMR algorithm
| 计算方法 | 优选特征名称 | 优选特征数目 |
|---|---|---|
| BD | NDVI均值、第1波段均值、NDWI均值、第3波段均值、第4波段均值、第1波段标准差、第2波段均值、角二阶矩、相关性、同质性、第2波段标准差、第3波段标准差、相异性、对比度、熵、第4波段标准差、NDWI标准差、NDVI标准差、长宽比、主方向 | 20 |
| HM | NDWI均值、第1波段均值、相关性、同质性、第4波段均值、第1波段标准差、NDVI均值、第3波段均值、第4波段标准差、角二阶矩、第2波段均值、相异性、第3波段标准差、第2波段标准差、熵、对比度、NDVI标准差、NDWI标准差 | 18 |
| F | NDWI均值、NDVI均值、第4波段均值、第3波段均值、相关性 | 5 |
表2的特征优选结果显示,虽然实验中采用相同原理的mRMR算法和相同的终止条件(即若式(2)或式(6)的值为零,则优选过程结束)进行特征优选,但3组计算方法所得结果也有所不同。其中,BD与HM方法所得优选结果特征数目较接近,BD方法只比HM方法多保留了长宽比及主方向2个特征。而F方法所得结果与其他2种方法差别较大,这是由于F方法虽然在实现原理上也是基于mRMR算法,但其用F统计量与皮尔逊相关系数代替互信息作为衡量相关性的标准,在一定程度上会导致计算结果的差异。
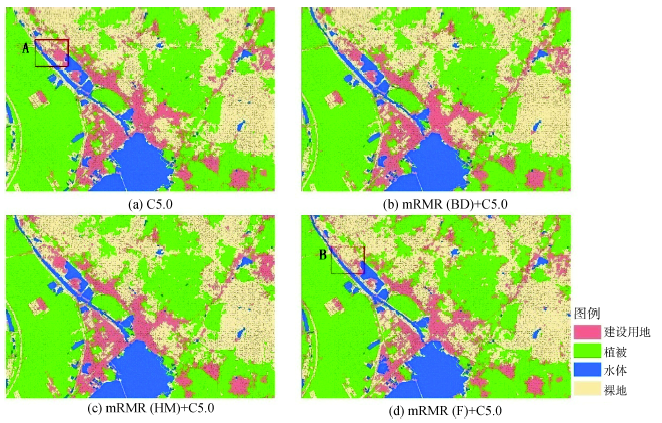
依据上述不同的特征优选结果,在利用C5.0和KNN分类器进行图像分类时,基于每种分类器分别进行4组对比实验:基于全部特征的分类、基于BD方法特征优选结果的分类、基于HM方法特征优选结果的分类和基于F方法特征优选结果的分类。分类实验效果图中的建设用地、植被、水体、裸地地物类型分别用红色、绿色、蓝色、浅黄色表示(图4、5)。
由图4、5可发现,利用每种分类器进行4组对比实验的分类结果大体相近,参照图3的研究区影像图,分类效果图中地物类型的划分也较为清晰,这表明利用相同分类器基于mRMR特征优选结果进行分类,对分类结果影响不大,从而体现出优选过程的合理性。仔细观察分类结果还可发现,不同实验结果在部分区域也会有一定差别。例如,图4中的A、B区域表示同一区域利用不同方法得到的分类结果,可以看出二者在对建设用地及裸地地物的分类上存在明显差异,这表明特征优选也会在一定程度上影响分类器的分类结果。
3.3.1 C5.0决策树分类结果分析
综合考虑基于C5.0分类器4组方法组合实验过程的分类效率与精度,给出对比分析结果,如表3所示。
表3 C5.0分类效率精度对比
Tab. 3 Comparison of the efficiency and accuracy between C5.0 classification methods
| 方法组合 | 分类时间/s | 总体分类精度/(%) | Kappa系数 |
|---|---|---|---|
| C5.0 | 1.349 | 83.5 | 0.747 |
| C5.0+BD | 1.209 | 82.0 | 0.724 |
| C5.0+HM | 1.157 | 84.0 | 0.753 |
| C5.0+F | 0.852 | 82.0 | 0.725 |
从分类效率角度对表3进行分析。3种方法组合均可提高分类器的分类效率,其中,C5.0+F分类所用时间仅为0.852 s,与C5.0方法相比在分类效率上提高了36.84%;而C5.0+BD与C5.0+HM相比于C5.0方法在分类效率上分别提高了10.38%、14.23%。本文实验所提取的特征数目总量为27个,样本数目为10 449个。由于C5.0决策树本身是一种较为高效及成熟的分类器模型,所以即便不进行特征优选而利用全部特征进行分类,分类时间也仅为1.349 s。但随着特征优选过程剔除的特征数目越多,分类时间不断减少,C5.0+BD、C5.0+HM、C5.0+F3种方法分别剔除了7、9、22个特征,其分类时间均少于利用全部特征进行分类的时间。虽然特征优选过程也需消耗一定时间,而且对于小样本数据而言,C5.0分类器具有较高的分类效率,但是特征优选所得结果可以重复利用于同组特征信息的多次研究中,通过特征优选也可得出不同地物类别与特征间的对应关系,从而在类似的研究中广泛应用。由此可见,mRMR特征优选算法可有效地提高C5.0的分类效率。
从分类精度对表3进行分析。3种方法组合均可保证分类精度大体不变,其中,C5.0+HM方法分类精度最高,总体分类精度与Kappa系数分别达到了84%、0.753,与C5.0方法相比精度略有提高,分别提高了0.6%及0.8%;而C5.0+BD与C5.0+F 2种方法分类精度均略低于C5.0方法。表3中数据表明总体分类精度和Kappa系数2种度量分类精度的参数呈正相关关系,这证明了实验结果的准确性。由于C5.0方法在分类过程中可通过将连续变量离散化来计算不同特征值的出现概率,从而以最大信息增益为标准选择特征进行建树,并依据决策树进行分类,这与mRMR特征优选算法在原理上存在一定相似性。并且C5.0在建树时不一定会用到全部特征,从而降低了错误特征信息对分类结果的影响,由此导致mRMR特征优选并没有显著提高C5.0的分类精度。但mRMR特征优选可以在保证精度基本不变的情况下,剔除掉一些对分类影响不大的特征,从而减少数据存储空间。
3.3.2 K近邻分类结果分析
对比分析基于KNN分类器4组方法组合实验过程的分类效率与精度,其结果如表4所示。
表4 KNN分类效率精度对比
Tab. 4 Comparison of the efficiency and accuracy between KNN classification methods
| 方法组合 | 分类时间/s | 总分类精度/(%) | Kappa系数 |
|---|---|---|---|
| KNN | 276.014 | 80.5 | 0.696 |
| KNN+BD | 212.306 | 84.0 | 0.751 |
| KNN+HM | 195.178 | 82.0 | 0.719 |
| KNN+F | 77.156 | 81.0 | 0.705 |
从分类效率对表4进行分析。3种方法组合均可以显著提高分类器的分类效率,KNN+BD、KNN+HM、KNN+F方法组合相比于KNN方法效率分别提高了23.08%、29.29%、72.05%。与C5.0分类器相比,KNN分类算法的复杂度较高,将表4统计结果与表3进行比较,可以明显反映出2种分类器在分类时间上的差异。对于本文实验而言,分类时间几乎相差100倍。本文实验的样本总数为10 449个,特征总数为27个,对于任意一个待测样本,在分类时均需计算其与已知1591个样本之间的欧式距离,计算量相对较大。考虑KNN分类器自身原理特点,利用mRMR进行特征优选以剔除冗余特征,可大大提高其分类效率。KNN+BD、KNN+HM及KNN+F 3组方法组合在特征优选过程中分别剔除了7、9、22个特征,且随着剔除特征的逐渐增多,分类效率也相应提高。在3种方法中,KNN+F方法可以将KNN分类器效率提高72.05%,在分类时间上节省近200 s,这充分证明mRMR特征优选可有效提高KNN分类效率,而对于更大的实验数据而言,特征优选过程则更为重要。
从分类精度对表4进行分析。3种方法组合均可以提高分类器的分类精度,其中KNN+BD方法拥有最高的分类精度,其在总分类精度及Kappa系数上相比于KNN方法可分别提高4.34%、7.90%。与表3实验结果类似,表4中不同实验方法的总分类精度及Kappa系数同样呈正相关,这表明了精度检验结果的可靠性。在4组实验的比较中,3组经过特征优选过程的分类结果精度均比利用KNN基于全部特征进行分类精度高,这表明对于KNN分类器而言,全部27个特征中存在一些冗余特征,从而影响分类器分类精度。KNN分类器在进行分类时需计算样本间的欧式距离,但在计算过程中并没有对参与计算的特征的重要性进行区别;而且不同特征数据单位、类型均可能不相同,虽然在计算中可以通过归一化的方式对数据进行预处理,也可通过设置权重的方式体现出不同特征的重要性差异,但如何量化权重大小也需进一步研究。所以,利用mRMR特征优选剔除在分类过程中易造成误差的冗余特征数据,会有效提高KNN分类器的分类 精度。
目前,在遥感领域比较常用的特征优选方法包括主成分分析、独立成分分析与流形学习等。为比较mRMR算法与其他方法在多光谱遥感数据方面的优选效果差异,本文以主成分分析方法为例,按照相同实验流程,利用主成分分析法基于同一研究区域影像数据进行实验。
对分类结果进行检验分析,并对全部方法组合实验结果进行统计,具体结果如表5所示。
从表5的2种优选方法的对比可看出,利用主成分分析所得结果进行影像分类,分类器效率高于mRMR算法,但其总体分类精度及Kappa系数不如mRMR算法。
表5 基于不同特征优选算法分类效率精度对比
Tab. 5 Comparison of the efficiency and accuracy between different feature selection methods
| 方法组合 | 分类时间/s | 总体分类精度/(%) | Kappa系数 |
|---|---|---|---|
| C5.0 | 1.349 | 83.5 | 0.747 |
| C5.0+mRMR | 1.073 | 82.7 | 0.734 |
| C5.0+PCA | 0.924 | 78.0 | 0.658 |
| KNN | 276.014 | 80.5 | 0.696 |
| KNN+mRMR | 161.547 | 82.3 | 0.725 |
| KNN+PCA | 88.303 | 80.0 | 0.689 |
mRMR算法依据不同的计算方法,优选得到的特征数目不同,所以在后续的分类过程中,不同方法对分类器效率的提高程度也有所不同。从整体来看,在效率的提高方面略逊于主成分分析,但mRMR算法考虑了特征与类别标签的相互关系,最终所优选出的特征均能很好地为分类服务,所以对分类器精度的提高程度也更明显。在数据的适应性方面,无论是连续型还是离散型数据均适用于mRMR算法,且在概率计算过程中可以弱化异常样本值,不会对整体优选结果产生很大影响。
而主成分分析则需进行数据标准化、相关系数矩阵计算、主成分函数表达式计算等过程,并根据求出的主成分函数表达式对原始数据进行处理,与mRMR算法计算过程相比,主成分分析更复杂,且对数据要求高,个别样本异常值的出现可能会造成数据标准化处理错误,从而导致整体结果出现较大误差。而且主成分分析在计算过程中并没有考虑特征与类别标签之间的关系,仅依据特征间关系划分成分,易造成关键信息丢失,从而降低分类器分类精度;但经过主成分分析后,将大量特征信息 合成为主成分有效降低了特征数目,提高了分类 效率。
本文通过实验证明了mRMR特征优选算法在多光谱影像分类过程中的有效性。对于C5.0分类器,3种方法组合均可提高分类效率,其中C5.0+F分类效率最高,可提高36.84%;而在精度方面,3种方法组合均可保证分类精度大致不变,其中C5.0+HM具有最高的分类精度,相比于C5.0分类结果,总体分类精度提高了0.60%,Kappa系数提高了0.80%。对于KNN分类器,总体提升效果比C5.0分类器更为显著,3种方法均可提高分类效率同时提高分类精度,KNN+F可提高分类效率72.05%,而KNN+BD则可将总体分类精度和Kappa系数分别提升4.34%、7.90%。但不同方法组合对于同一分类器的提升效果也有所不同,由此则需在进行影像分类时,依据所采用的分类器以及研究目的,选择最合适的计算方法实现mRMR优选过程,本文只采用了3种计算方法,后续的研究还可以对Parzon窗[24]、Leonenko[16]等其他计算方法进行实验。在实验过程中,影像分割、特征提取、样本选择等过程均会对分类过程造成影响,为更好地验证特征优选效果,需保证在上述过程中不产生过多误差,后续的研究也可在这些方面进行深入探讨。
The authors have declared that no competing interests exist.
| [1] |
论21世纪遥感与GIS的发展 [J].Towards the development of remote sensing and GIS in the 21st century [J]. |
| [2] |
基于决策树方法的蒙古高原土地覆盖遥感分类——以蒙古国中央省为例 [J].https://doi.org/10.3724/SP.J.1047.2014.00460 URL Magsci [本文引用: 1] 摘要
<p>蒙古高原包括蒙古全部、俄罗斯南部和中国北部部分地区。蒙古高原的土地利用/覆盖格局与变化,对揭示该区域乃至整个东北亚地区的资源、环境和生态特征,促进该区域可持续发展具有重要的现实和科学意义。本文以在蒙古国中央省及其所含首都乌兰巴托市为研究区,利用空间分辨率为30m的TM影像,采取QUEST(Quick Unbiased and Efficient Statistical Tree)决策树方法,通过图像目视解译,获取了研究区2010年土地覆盖分类数据。结果显示,草地占据研究区总面积的70.88%,其次是森林占14.83%、裸地占10.73%、农田占2.98%、水体占0.31%、建筑用地占0.27%、湿地占0.02%。通过野外实地采集的139个GPS验证点进行精度评价发现,一级土地覆盖类型的总体精度可达72.66%。针对草地的二级分类的总体精度有较明显下降,其主要是由于中蒙科学家对于草地类型分类体系的差异所造成的典型草地和荒漠草地的混分。</p>
Land cover classification in Mongolian Plateau based on decision tree method: a case study in Tov Province, Mongolia [J].https://doi.org/10.3724/SP.J.1047.2014.00460 URL Magsci [本文引用: 1] 摘要
<p>蒙古高原包括蒙古全部、俄罗斯南部和中国北部部分地区。蒙古高原的土地利用/覆盖格局与变化,对揭示该区域乃至整个东北亚地区的资源、环境和生态特征,促进该区域可持续发展具有重要的现实和科学意义。本文以在蒙古国中央省及其所含首都乌兰巴托市为研究区,利用空间分辨率为30m的TM影像,采取QUEST(Quick Unbiased and Efficient Statistical Tree)决策树方法,通过图像目视解译,获取了研究区2010年土地覆盖分类数据。结果显示,草地占据研究区总面积的70.88%,其次是森林占14.83%、裸地占10.73%、农田占2.98%、水体占0.31%、建筑用地占0.27%、湿地占0.02%。通过野外实地采集的139个GPS验证点进行精度评价发现,一级土地覆盖类型的总体精度可达72.66%。针对草地的二级分类的总体精度有较明显下降,其主要是由于中蒙科学家对于草地类型分类体系的差异所造成的典型草地和荒漠草地的混分。</p>
|
| [3] |
基于遥感影像的军事阵地动态监测技术研究 [J].https://doi.org/10.11873/j.issn.1004-0323.2014.3.0511 URL [本文引用: 1] 摘要
针对部队快速机动作战的军事要求,提出基于高分辨率遥感影像的军用阵地动态监测方法。借助面向对象的多尺度分割技术将阵地影像分割为同质对象,以提取各个对象的特征;针对监督分类和非监督分类的弊端,提出通过一定的先验知识制定分类规则的方法对遥感影像进行地物识别,在此基础上定性和定量地输出变化检测结果。实验结果表明:利用基于对象影像分析方法具有较高的识别精度,能够有效监测军事阵地变化。
Dynamic monitoring of military position based on remote sensing image [J].https://doi.org/10.11873/j.issn.1004-0323.2014.3.0511 URL [本文引用: 1] 摘要
针对部队快速机动作战的军事要求,提出基于高分辨率遥感影像的军用阵地动态监测方法。借助面向对象的多尺度分割技术将阵地影像分割为同质对象,以提取各个对象的特征;针对监督分类和非监督分类的弊端,提出通过一定的先验知识制定分类规则的方法对遥感影像进行地物识别,在此基础上定性和定量地输出变化检测结果。实验结果表明:利用基于对象影像分析方法具有较高的识别精度,能够有效监测军事阵地变化。
|
| [4] |
城市建筑物人口时空分布模型与实验分析——以北京东华门街道为例 [J].https://doi.org/10.3724/SP.J.1047.2013.00019 Magsci [本文引用: 1] 摘要
精细尺度上的城市人口分布是解决城市规划与管理、预警与应急等问题的关键。研究精细尺度上城市人口的时空分布需要还原与模拟城市人口与城市建筑物之间的关系。本文利用高分辨率遥感影像提取城市精细尺度的建筑物信息,建立了适用于城市人口分布研究的城市建筑物功能分类体系,并获取了不同使用功能的建筑物人口容纳系数;在实际调查和前人研究的基础上得到不同使用功能的城市建筑物人口吸引率曲线,建立城市建筑物人口分布模型,实现城市精细尺度上的人口分布情况的模拟。以北京东华门街道为例,对16个时间点(0:00、6:00、7:00、8:00、9:00、10:00、11:00、12:00、13:00、14:00、15:00、16:00、17:00、18:00、19:00、22:00)的城市建筑物人口分布情况进行了模拟,并根据建筑物功能的聚集及道路空间分割情况划分为4个区域进行了人口数量变化分析和原因探讨。最后,讨论了研究中存在的问题,并提出了增加实际调查数据等可能的改进方法。
Simulation of urban small-area population space-time distribution based on building extraction: taking Beijing Donghuamen subdistrict as an example [J].https://doi.org/10.3724/SP.J.1047.2013.00019 Magsci [本文引用: 1] 摘要
精细尺度上的城市人口分布是解决城市规划与管理、预警与应急等问题的关键。研究精细尺度上城市人口的时空分布需要还原与模拟城市人口与城市建筑物之间的关系。本文利用高分辨率遥感影像提取城市精细尺度的建筑物信息,建立了适用于城市人口分布研究的城市建筑物功能分类体系,并获取了不同使用功能的建筑物人口容纳系数;在实际调查和前人研究的基础上得到不同使用功能的城市建筑物人口吸引率曲线,建立城市建筑物人口分布模型,实现城市精细尺度上的人口分布情况的模拟。以北京东华门街道为例,对16个时间点(0:00、6:00、7:00、8:00、9:00、10:00、11:00、12:00、13:00、14:00、15:00、16:00、17:00、18:00、19:00、22:00)的城市建筑物人口分布情况进行了模拟,并根据建筑物功能的聚集及道路空间分割情况划分为4个区域进行了人口数量变化分析和原因探讨。最后,讨论了研究中存在的问题,并提出了增加实际调查数据等可能的改进方法。
|
| [5] |
Band selection in multispectral images by minimization of dependent information [J]. |
| [6] |
基于ReliefF+mRMR特征降维算法的多特征遥感图像分类 [J].Multiple features remote sensing image classification based on combining ReliefF and mRMR [J]. |
| [7] |
基于主成分分析的综合评价研究 [D].Comprehensive assessment study based on principal component analysis [D]. |
| [8] |
独立成分分析的若干算法及其应用研究 [D].Several algorithms for independent component analysis and their applications [D]. |
| [9] |
基于流形学习的特征提取方法及其应用研究 [D].The study of the manifold learning based feature extraction methods and their applications [D]. |
| [10] |
Feature selection based on mutual information: criteria of max-dependency, max-relevance, and min-redundancy [J]. |
| [11] |
特征选择方法综述 [J].
<p>特征选择是模式识别的关键问题之一, 特征选择结果的好坏直接影响着分类器的分类精度和泛化性能. 首<br />先分析了特征选择方法的框架; 然后从搜索策略和评价准则两个角度对特征选择方法进行了分析和总结; 最后分析<br />了对特征选择的影响因素, 并指出了实际应用中需要解决的问题.</p>
Summary of feature selection algorithms [J].
<p>特征选择是模式识别的关键问题之一, 特征选择结果的好坏直接影响着分类器的分类精度和泛化性能. 首<br />先分析了特征选择方法的框架; 然后从搜索策略和评价准则两个角度对特征选择方法进行了分析和总结; 最后分析<br />了对特征选择的影响因素, 并指出了实际应用中需要解决的问题.</p>
|
| [12] |
Minimum redundancy feature selection from microarray gene expression data [J].https://doi.org/10.1109/CSB.2003.1227396 URL PMID: 15852500 [本文引用: 4] 摘要
Selecting a small subset of genes out of the thousands of genes in microarray data is important for accurate classification of phenotypes. Widely used methods typically rank genes according to their differential expressions among phenotypes and pick the top-ranked genes. We observe that feature sets so obtained have certain redundancy and study methods to minimize it. Feature sets obtained through the minimum redundancy - maximum relevance framework represent broader spectrum of characteristics of phenotypes than those obtained through standard ranking methods; they are more robust, generalize well to unseen data, and lead to significantly improved classifications in extensive experiments on 5 gene expressions data sets.
|
| [13] |
面向对象影像分类中基于最大化互信息的特征选择 [J].https://doi.org/10.6046/gtzyyg.2009.03.06 Magsci [本文引用: 1] 摘要
<p>高分辨率影像面向对象分割后产生了大量的光谱、形状以及纹理特征,如何抽取出最佳特征子集是遥感影像识别的重要问题。本文利用最大化互信息统计独立准则抽取最优特征子集,提高了面向对象遥感影像分类精度。基本过程包含以下3个方面: 首先,利用eCoginition软件对高分辨遥感影像进行对象分割; 然后,基于互信息最大关联、最小冗余准则(mRMR)获取优选的特征子集; 最后,基于支持向量机分类器完成影像分类。以福建省漳州市QuickBird数据为例的实验表明,该方法能够有效提高遥感影像的分类精度,平均误分率降低了约4%。</p>
Feature selection based on maxmal mutual information criterion in object-oriented classification [J].https://doi.org/10.6046/gtzyyg.2009.03.06 Magsci [本文引用: 1] 摘要
<p>高分辨率影像面向对象分割后产生了大量的光谱、形状以及纹理特征,如何抽取出最佳特征子集是遥感影像识别的重要问题。本文利用最大化互信息统计独立准则抽取最优特征子集,提高了面向对象遥感影像分类精度。基本过程包含以下3个方面: 首先,利用eCoginition软件对高分辨遥感影像进行对象分割; 然后,基于互信息最大关联、最小冗余准则(mRMR)获取优选的特征子集; 最后,基于支持向量机分类器完成影像分类。以福建省漳州市QuickBird数据为例的实验表明,该方法能够有效提高遥感影像的分类精度,平均误分率降低了约4%。</p>
|
| [14] |
结合邻域相关影像与最大相关性最小冗余性特征选择的面向对象变化检测 [J].https://doi.org/10.11834/jig.20140120 URL [本文引用: 1] 摘要
目的针对两期高分辨率遥感影像,提出一种结合邻域相关影像(NCI)和最大相关性最小冗余性特征选择(mRMR)的面向对象变化检测方法。方法为了验证该方法的有效性,设计了3组对比实验:1)只使用mRMR特征选择与未使用mRMR特征选择的效果比较;2)使用NCI与mRMR特征选择相结合与只使用NCI的效果比较;3)使用NCI与mRMR特征选择相结合与只使用mRMR特征选择的效果比较。结果实验结果表明,使用NCI与mRMR特征选择相结合的变化检测效果要优于只使用NCI或是只使用mRMR特征选择的效果,更优于两者都不使用的效果。结论理论上本文方法并不会因为采用了不同的高分辨率遥感数据源而影响其对变化检测的优越性,实际情况是否如此,还需进一步通过实验验证。
The object-oriented change detection based on neighborhood correlation images and the minimum-redundancy-maximum-relevance feature selection [J].https://doi.org/10.11834/jig.20140120 URL [本文引用: 1] 摘要
目的针对两期高分辨率遥感影像,提出一种结合邻域相关影像(NCI)和最大相关性最小冗余性特征选择(mRMR)的面向对象变化检测方法。方法为了验证该方法的有效性,设计了3组对比实验:1)只使用mRMR特征选择与未使用mRMR特征选择的效果比较;2)使用NCI与mRMR特征选择相结合与只使用NCI的效果比较;3)使用NCI与mRMR特征选择相结合与只使用mRMR特征选择的效果比较。结果实验结果表明,使用NCI与mRMR特征选择相结合的变化检测效果要优于只使用NCI或是只使用mRMR特征选择的效果,更优于两者都不使用的效果。结论理论上本文方法并不会因为采用了不同的高分辨率遥感数据源而影响其对变化检测的优越性,实际情况是否如此,还需进一步通过实验验证。
|
| [15] |
|
| [16] |
基于信息熵和互信息的流域水文模型不确定性分析 [D].Watershed model uncertainty analysis based on information entropy and mutual information [D]. |
| [17] |
Comparison of discrimination methods for the classification of tumors using gene expression data [J].https://doi.org/10.1198/016214502753479248 URL [本文引用: 2] 摘要
1. INTRODUCTIONA reliable and precise classification of tumors is essential for successful diagnosis and treatment of cancer. Current methods for classifying human malignancies rely on a variety of morphological, clinical, and molecular variables. Despite recent progress, there are still uncertainties in diagnosis. Furthermore, it is likely that the existing classes are heterogeneous and comprise diseases that are molecularly distinct and follow different clinical courses. cDNA microarrays and high-density oligonucleotide chips are novel biotechnologies increasingly used in cancer research (Alon et al. 1999; Golub et al. 1999; Perou et al. 1999; Pollack et al. 1999; Alizadeh et al. 2000; Ross et al. 2000). By allowing the monitoring of expression levels in cells for thousands of genes simultaneously, microarray experiments may lead to a more complete understanding of the molecular variations among tumors and hence to a finer and more reliable classification.Types of microarray systems include the cDNA microarrays developed in the Brown and Botstein labs at Stanford (DeRisi, Iyer, and Brown 1997; Eisen, Spellman, Brown, and Botstein 1998) and the high-density oligonucleotide chips from the Affymetrix Company (Lockhart et al. 1996); the brief description here focuses on the former. cDNA microarrays consist of thousands of individual DNA sequences printed in a high-density array on a glass microscope slide using a robotic arrayer. The relative abundance of these spotted DNA sequences in two DNA or RNA samples may be assessed by monitoring the differential hybridization of the two samples to the sequences on the array. For mRNA samples, the two samples, or targets, are reverse-transcribed into cDNA, labeled using different fluorescent dyes [e.g., a red fluorescent dye (cyanine 5 or Cy5), and a green fluorescent dye (cyanine 3 or Cy3)], then mixed in equal proportions and hybridized with the arrayed DNA sequences, or probes (following the definition of probe and targ et adopted in The Chipping Forecast 1999). After this competitive hybridization, the slides are imaged using a scanner and fluorescence measurements are made separately for each dye at each spot on the array. The ratio of the red and green fluorescence intensities for each spot is indicative of the relative abundance of the corresponding DNA probe in the two nucleic acid target samples. (See The Chipping Forecast 1999 for a more detailed introduction to the biology and technology of cDNA microarrays and oligonucleotide chips.)Microarray experiments raise numerous statistical questions in fields as diverse as image analysis, experimental design, cluster and discriminant analysis, and multiple hypothesis testing. Here we focus on the classification of tumors using gene expression data. Three main types of statistical problems are associated with tumor classification: (a) identification of new tumor classes using gene expression profiles, cluster analysis/unsupervised learning; (b) classification of malignancies into known classes, discriminant analysis/supervised learning; and (c) identification of "marker" genes that characterize the different tumor classes, variable selection. Data from these new types of experiments present a "large p, small n" problem; that is, a very large number of variables (genes) relative to the number of observations (tumor samples). The publicly available datasets typically contain expression data on 5,000-10,000 genes for less than 100 tumor samples. Both numbers are expected to grow, the number of genes reaching on the order of 30,000, an estimate for the total number of genes in the human genome.Recent publications on cancer classification using gene expression data have focused mainly on the cluster analysis of both tumor samples and genes and include applications of hierarchical clustering (Alon et al. 1999; Perou et al. 1999; Pollack et al. 1999; Alizadeh et al. 2000; Ross et al. 2000) and 鈥
|
| [18] |
Top 10 algorithms in data mining [J].https://doi.org/10.1007/s10115-007-0114-2 URL Magsci [本文引用: 2] 摘要
<a name="Abs1"></a>This paper presents the top 10 data mining algorithms identified by the IEEE International Conference on Data Mining (ICDM) in December 2006: C4.5, <i>k</i>-Means, SVM, Apriori, EM, PageRank, AdaBoost, <i>k</i>NN, Naive Bayes, and CART. These top 10 algorithms are among the most influential data mining algorithms in the research community. With each algorithm, we provide a description of the algorithm, discuss the impact of the algorithm, and review current and further research on the algorithm. These 10 algorithms cover classification, clustering, statistical learning, association analysis, and link mining, which are all among the most important topics in data mining research and development.
|
| [19] |
|
| [20] |
基于决策树的数据挖掘算法研究与应用 [D].Research and application on the data mining algorithm based on decision tree [D]. |
| [21] |
基于发生学视角的淮南城市空间生长过程、特征及影响因素研究 [J].
<p>以淮南市为案例,结合历次城市规划用地现状资料和产业发展数据,利用GIS 技术平台,对不同考察时点淮南城市空间形态进行叠加对比研究、测算不同时期城市空间扩展形态紧凑度、扩展速度和扩展强度指数,从时间维度和空间维度2 个方面考察了淮南城市空间形态的演变过程及特征。结果表明:作为无依托型煤炭城市,淮南城市空间发展经历了散点发展、节点集聚扩展、飞地拓展、轴向延伸、内向填充、整合优化、区位再造7 个阶段,表现出显著的空间取向和圈层结构特征;在空间扩展过程中,深受资源分布的控制和煤炭产业的影响,城市空间围绕煤炭企业为中心生长扩展,导致城市空间从紧凑形态向分散发展,经多次嵌套填充、优化调整,再次向紧凑形态演化。分析认为,淮南在不同演化阶段,影响城市空间生长的主导因素有所差异:资源状况和通勤条件主导发生期城市空间形态、成长期受国家能源战略和交通运输的引导、中兴期则以产业结构演替为主导因素、转型期深受空间经济相互作用引导和规划调控的影响。</p>
Process, characteristics and influence factors of the Huainan City’s spatial expansion from the embryology perspective [J].
<p>以淮南市为案例,结合历次城市规划用地现状资料和产业发展数据,利用GIS 技术平台,对不同考察时点淮南城市空间形态进行叠加对比研究、测算不同时期城市空间扩展形态紧凑度、扩展速度和扩展强度指数,从时间维度和空间维度2 个方面考察了淮南城市空间形态的演变过程及特征。结果表明:作为无依托型煤炭城市,淮南城市空间发展经历了散点发展、节点集聚扩展、飞地拓展、轴向延伸、内向填充、整合优化、区位再造7 个阶段,表现出显著的空间取向和圈层结构特征;在空间扩展过程中,深受资源分布的控制和煤炭产业的影响,城市空间围绕煤炭企业为中心生长扩展,导致城市空间从紧凑形态向分散发展,经多次嵌套填充、优化调整,再次向紧凑形态演化。分析认为,淮南在不同演化阶段,影响城市空间生长的主导因素有所差异:资源状况和通勤条件主导发生期城市空间形态、成长期受国家能源战略和交通运输的引导、中兴期则以产业结构演替为主导因素、转型期深受空间经济相互作用引导和规划调控的影响。</p>
|
| [22] |
淮南市土壤重金属污染生态研究 [D].Ecological study on the soil heavy metal pollution in Huainan city [D]. |
| [23] |
迁移学习支持下的遥感影像对象级分类样本自动选择方法 [J].https://doi.org/10.13485/j.cnki.11-2089.2014.0163 URL Magsci [本文引用: 1] 摘要
<p>面向遥感大范围应用的目标,自动化程度仍是遥感影像分类面临的重要问题,样本的人工选择难以适应当前土地覆盖信息自动化提取的实际应用需求。为了构建一套基于先验知识的遥感影像全自动分类流程,本文将空间信息挖掘技术引入到遥感信息提取过程中,提出了一种面向遥感影像对象级分类的样本自动选择方法。该方法通过变化检测将不变地物标示在新的目标影像上,并将过去解译的地物类别知识迁移至新的影像上,建立新的特征与地物关系,从而完成历史专题数据辅助下目标影像的自动化的对象级分类。实验结果表明,在已有历史专题层的图斑知识指导下,该方法能有效地自动选择适用于新影像分类的可靠样本,获得较好的信息提取效果,提高了对象级分类的效率。</p>
An automatic sample collection method for object-oriented classification of remotely sensed imageries based on transfer learning [J].https://doi.org/10.13485/j.cnki.11-2089.2014.0163 URL Magsci [本文引用: 1] 摘要
<p>面向遥感大范围应用的目标,自动化程度仍是遥感影像分类面临的重要问题,样本的人工选择难以适应当前土地覆盖信息自动化提取的实际应用需求。为了构建一套基于先验知识的遥感影像全自动分类流程,本文将空间信息挖掘技术引入到遥感信息提取过程中,提出了一种面向遥感影像对象级分类的样本自动选择方法。该方法通过变化检测将不变地物标示在新的目标影像上,并将过去解译的地物类别知识迁移至新的影像上,建立新的特征与地物关系,从而完成历史专题数据辅助下目标影像的自动化的对象级分类。实验结果表明,在已有历史专题层的图斑知识指导下,该方法能有效地自动选择适用于新影像分类的可靠样本,获得较好的信息提取效果,提高了对象级分类的效率。</p>
|
| [24] |
Input feature selection by mutual information based on Parzen window [J].https://doi.org/10.1109/TPAMI.2002.1114861 URL [本文引用: 1] 摘要
Mutual information is a good indicator of relevance between variables, and have been used as a measure in several feature selection algorithms. However, calculating the mutual information is difficult, and the performance of a feature selection algorithm depends on the accuracy of the mutual information. In this paper, we propose a new method of calculating mutual information between input and class variables based on the Parzen window, and we apply this to a feature selection algorithm for classification problems.
|

/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}