张野 , 王康, 王菜林
, 王康, 王菜林
Zhang Ye, Wang Kang, Wang Cailin
中图分类号: K90
文献标识码: A
文章编号: 1000-0690(2017)04-0603-08
通讯作者:
收稿日期: 2016-09-22
修回日期: 2017-01-9
网络出版日期: 2017-04-25
版权声明: 2017 《地理科学》编辑部 本文是开放获取期刊文献,在以下情况下可以自由使用:学术研究、学术交流、科研教学等,但不允许用于商业目的.
基金资助:
作者简介:
作者简介:张野(1982-),男,黑龙江海伦人,博士研究生,主要从事区域可持续发展研究。E-mail:zhangy853@nenu.edu.cn
展开
摘要
以辽宁省宽甸县为例,利用1955~2012年逐日降水数据,提取年暴雨日数(D50)、年暴雨量(P50)、年均暴雨强度(I)和暴雨比(R)共4个暴雨要素,运用K-S法确定各单要素最优概率分布函数;针对暴雨要素多面性,通过引入Copula函数,构建三维联合分布并进行AIC和RMSE优度检验,确定适合暴雨要素的最优Copula函数,分析多要素联合后暴雨的概率和重现期特征。研究表明: ① 单变量拟合仅反映暴雨单个要素本身的信息,无法涉及要素间的联系;三维Copula联合可从3方面呈现暴雨要素间的内在信息,更贴近实际;暴雨本身的多要素性,为Copula函数在暴雨分析上提供了广阔前景; ② 年暴雨日数、年暴雨量和年均暴雨强度的联合适合反映宽甸县暴雨重现期;宽甸县暴雨联合重现期短,多为0~2 a,同现重现期较长,集中于200 a左右;2种重现期变化趋势一致,存在同步效应,反映了暴雨要素的不可分割性。
关键词:
Abstract
Taking Kuandian County in Liaoning Province as an example, the author extract four rainstorm factors: the annual rainstorm days, annual of rainstorm depth, annual average rainstorm intensity and rainstorm contribution, through the daily precipitation data from 1955 to 2012 and use the Kolmogorov-Smimov method to determine optimal probability distribution for each single factor. For the multifaceted rainstorm factor, we use AIC and RMSE test to confirm the best fitted copulas connect function suitable for rainstorm factor by introducing the copula function and building three-dimensional joint distribution, and analyze the probability of rainstorm and characteristics of return period with many combined factors. Research shows that: 1) The joint of annual rainstorm days, annual of rainstorm depth and annual average rainstorm intensity is suitable for reaction joint return period of rainstorm factor in Kuandian County; In Kuandian County, joint return period is short and distribute on 0-2 years, co-occurrence return period is longer, concentrated in around 200 years; the change trend of two kinds of return period is consistent, it has synchronization effect, this reflect inseparable of rainstorm factor. 2) The univariate reflect just one factor of information in rainstorm and doesn’t involved in the relationship between factors; Three-dimensional copulas joint can present the internal information between heavy elements from three aspects and closer to the actual; Multiple factors of rainstorm, as copulas function on the rainstorm analysis provides a broad prospects.
Keywords:
暴雨灾害是发生最频繁,影响最严重的自然灾害之一,中国每年因暴雨造成的灾害损失达千亿[1]。现阶段对暴雨灾害的研究多以风险区划表达区域潜在风险程度[2],却忽略暴雨致灾因子本身的多面性。暴雨致灾因子的研究,通常从年暴雨量、年暴雨日数、年暴雨强度以及暴雨量占全年降水比重方面着手分析时间和空间的变化差异[3,4]。也有学者分析暴雨频率以及重现期,探寻致灾因子发生可能性的研究,但多侧重于暴雨某一要素进行探讨[5,6]。以往研究清晰地展现了暴雨单要素特征,也表明暴雨是多要素共同作用的事件,为暴雨灾害研究提供了分析致灾因子的依据;然而,针对暴雨要素的多面性,要素之间存在何种关系,以及暴雨要素联合之后,暴雨又会呈现何种特征,往往被人们所忽略,这些成为暴雨灾害研究中薄弱的环节。
Copula函数是目前运用广泛,认可度高的一种多维联合分析的方法,其优势在于不需各变量有统一的边缘分布。现已在水文等多个领域获得运用[7,8],效果良好;灾害领域的运用则多侧重于旱灾[9,10],关于Copula函数的暴雨灾害研究并不多见[11~13]。虽然Copula函数的运用研究成果颇丰,但多是针对二维变量联合分布特征的探讨[14,15],从三维乃至更高维的角度运用Copula函数进行多变量的研究相对缺乏[16]。鉴于此,本文从暴雨要素的多面性出发,利用Copula函数多维联合的灵活性,构建4对三维联合分布,探讨年暴雨日数、年暴雨量、年均暴雨强度以及暴雨比这4要素的内在概率分布特征以及联合重现期和同现重现期的变化情况,揭示多要素背景下暴雨特征,为区域暴雨研究提供新的思路。
以国家气象信息中心提供的辽宁丹东宽甸站1955~2012年逐日降水数据为基础,采用中国气象部门规定的50 mm为暴雨阈值[17],提取历年发生暴雨日数(D50),统计历年暴雨量(P50);以≥0.1 mm为有雨日,统计年降水总量(P);以P50/D50为年均暴雨强度I,P50/P为暴雨比(R)。
1.2.1 暴雨要素边缘分布构建
本文选取正态分布(NORM)、泊松分布(POISS),指数分布(EXP)、极值分布(EV)、广义极值分布(GEV)和广义帕累托分布(GP)6种函数进行暴雨要素边缘分布拟合,采用极大似然函数公式(1)~(3)进行边缘分布参数估计。
式中,L(θ)为似然函数,F(xi;θ)为边缘分布密度函数,θ为待估参数。进一步应用Kolmogorov-Smirnov 2(K-S2)作各边缘分布拟合优度检验,确定适合各暴雨要素的概率分布函数。
1.2.2 暴雨要素三维联合分布构建
本文选用4种Copula函数进行暴雨要素三维联合[18],具体如下:
通过表1中Copula函数进行三维拟合,采用均方根误差(RMSE)和赤池信息量准则(Akaike Information Criterion, AIC)对Copula拟合效果进行优度检验,以确定满足表1参数范围的最优Copula函数,优度检验公式如下:
式中,Pei为暴雨要素三维联合经验概率,Pi为Copula函数联合分布值,l为模型中所含参数个数。检验值RMSE与AIC越小,表示Copula分布值Pi越靠近与三维联合经验概率值Pei,拟合精度越高。
表1 4种三维Copula分布函数及参数范围
Table 1 Four kinds of three-dimensional Copula distribution function and parameter range
| 分布函数 | 参数范围 | |
|---|---|---|
| Frank | (–∞,∞)\{0} | |
| Clayton | [-1,∞]\{0} | |
| Gumbel | [1,∞] | |
| AMH | [-1,1] |
1.2.3 暴雨要素重现期
由重现期相关理论可知,各要素大于或等于某一定值的重现期为:
式中,T为暴雨4要素的单变量重现期,F(X)为各要素的边缘分布,N为观测样本长度,n为观测时段内超越某一给定样本出现的次数。Copula三维联合重现期为:
三维同现重现期为:
式中,
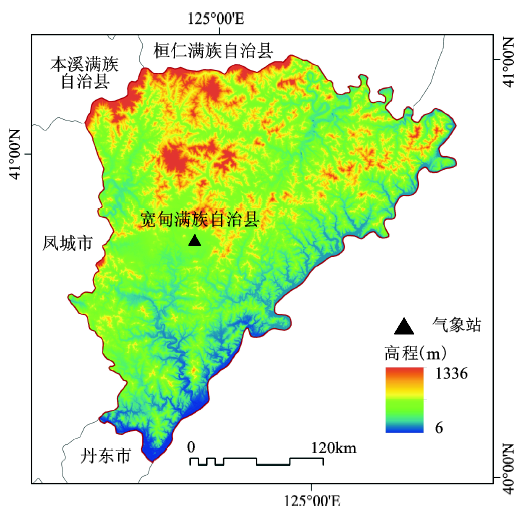
宽甸县位于中国东北地区辽宁省东南部,124°21′E~125°42′ E,40°13′N~41°9′ N(图1);地势自西北向东南倾斜,西北部平均海拔500 m,山地最高可达133 6 m;东南部平均海拔10 m,山地一般为300~500 m。本区为温带半湿润季风气候区,四季分明,雨热同期,受东南季风和西南季风以及复杂地形的影响,暴雨频发,年均暴雨天数在4 d左右,比东北其他地区多2~3 d,年均暴雨总量为350 mm,占年降水总量的1/3,日降水最高可达657 mm;降水丰年,暴雨日数和暴雨量是平均值的2~3倍,因此成为东北境内暴雨中心区[19,20]。
运用公式(1)~(3)极大似然函数进行暴雨要素6种概率分布的参数估计,通过K-S2返回的P值进行检验。P值用于反映拟合函数是否能通过给定显著性检验水平的可能性,当P值大于显著水平时,则通过检验,P值越大,通过检验的可能性越高。检验显著性水平取值0.05,得到各暴雨要素的拟合优度(表2)。
表2 暴雨要素边缘分布K-S2检验值
Table 2 K-S2 test value of rainstorm factors marginal distribution
| D50 | I | P50 | R | |
|---|---|---|---|---|
| GEV | 0.1397* | 0.975* | 0.8935* | 0.9985* |
| EV | 0.0176 | 0.2135* | 0.088* | 0.7558* |
| EXP | 0.0313 | 0.0535* | 0.0000 | 0.0025 |
| POISS | 0.1397* | 0.0000 | 0.0535* | 0.0000 |
| NORM | 0.0006 | 0.0000 | 0.0000 | 0.0001 |
| GP | 0.088* | 0.4426* | 0.0006 | 0.1397* |
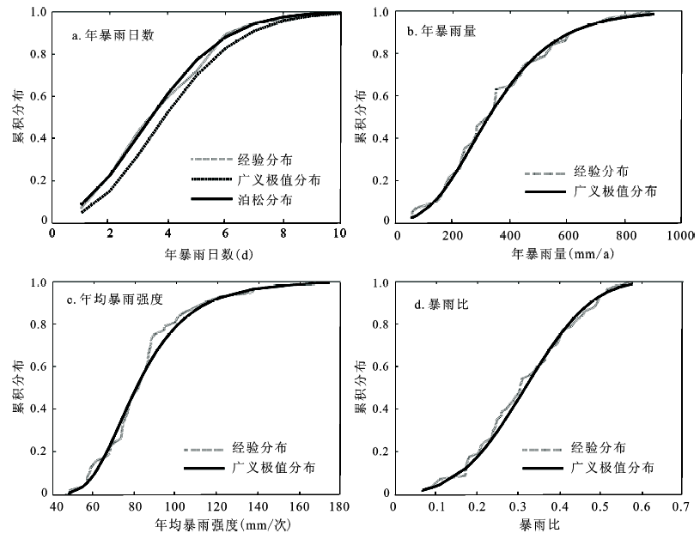
由表2可知,正态分布(NORM)不适合用于上述暴雨要素的拟合;指数分布(EXP)只在年均暴雨强度I上通过检验,且P值与显著水平0.05差距较小,拟合效果微弱;泊松分布(POISS)适合对年暴雨日数进行拟合;其他分布均能同时通过3个及以上暴雨要素的拟合检验,且拟合效果较好,广义极值(GEV)对暴雨比的拟合效果尤为明显(图2)。通过对比检验值P和曲线拟合图(图2),得知年均暴雨强度、年暴雨量以及暴雨比在0.05显著性水平上比较适合运用广义极值分布进行拟合。虽然年暴雨日数同时通过广义极值、泊松和广义帕累托分布拟合,且GEV与POISS返还的P值相同,但由图2可知,泊松分布曲线明显比广义极值曲线更接近于年暴雨日数的经验分布曲线,所以年暴雨日数的边缘分布采用泊松分布进行拟合。符合各暴雨要素的分布函数及参数(见表3)。
表3 暴雨要素边缘分布函数及参数
Table 3 Rainstorm factors marginal distribution function and parameters
| 暴雨要素 | 边缘分布 | 参数值 |
|---|---|---|
| D50 | k=4.1579 | |
| I | k=0.0012 | |
| s=1.5709 | ||
| m=2.6711 | ||
| P50 | k=0.0704 | |
| s=16.964 | ||
| m=74.13 | ||
| R | k=-0.296 | |
| s=0.1224 | ||
| m=0.3784 |
从暴雨要素的拟合曲线(图2)可知年暴雨日数、年暴雨量、年均暴雨强度的累积概率顶部变化趋势平缓,意味着一年中发生暴雨较多的天数(8~10 d)以及平均暴雨强度在140~180 mm/次和暴雨积累量在800~1 000 mm/a的情况很少见,暴雨强度累积概率曲线最陡,降雨主要集中在60~120 mm;而暴雨比顶部变化与其中部相对一致,分布较均匀,不存在明显集中区域。单要素曲线拟合所提供的仅为要素本身的相关信息,但对于具有多要素的暴雨而言,在纵向分析的同时,还需侧重横向的联系。
从年暴雨日数、年暴雨量、年均暴雨强度和暴雨比中选取3个要素构建4对Copula三维联合分布,利用公式(1)~(3)进行Copula参数估计,采用表1中Copula分布函数公式进行三维拟合,通过公式(4)进行优度检验,相关参数及检验值见表4。
表4 Copula 三维联合分布函数参数及检验值
Table 4 The parameters and test values of three-dimensional Copula distribution function
| 分布函数 | 参数及检验 | D50、I& P50 | D50、I&R | D50、P50&R | I、P50&R |
|---|---|---|---|---|---|
| Frank | 参数 | 2.5117 | 13.9572 | 1.9848 | 5.5522 |
| RMSE | 0.0521 | 0.0514 | 0.1658 | 0.1585 | |
| AIC | -290.88 | -292.448 | -161.2544 | -162.274 | |
| Clayton | 参数 | 0.626 | 5.1859 | 0.3154 | 1.0428 |
| RMSE | 0.0558 | 0.0531 | 0.1467 | 0.1430 | |
| AIC | -283.1862 | -288.7487 | -174.958 | -173.87 | |
| Gumbel | 参数 | 1.2828 | 2.995 | 1.1973 | 1.8666 |
| RMSE | 0.0572 | 0.0659 | 0.1724 | 0.1646 | |
| AIC | -280.5228 | -264.6426 | -156.9166 | -158.042 | |
| AMH | 参数 | 0.379 | 0.9189 | 0.5705 | 0.8541 |
| RMSE | 0.0541 | 0.0542 | 0.1752 | 0.1766 | |
| AIC | -286.5932 | -286.5251 | -155.0723 | -150.187 |
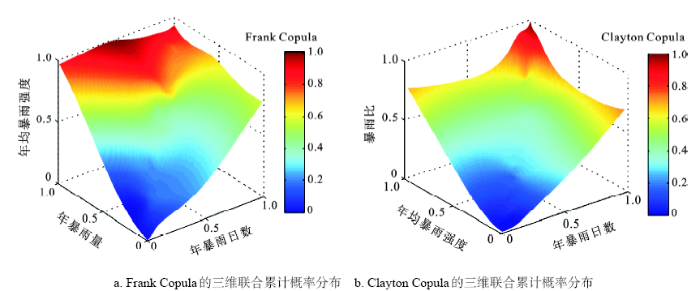
由表4可知,似然参数估计值均满足所选Copula函数的参数要求,采用 RMSE和AIC最小原则,选用Frank Copula为年暴雨日数、年均暴雨强度和年暴雨量以及年暴雨日数、年均暴雨强度和暴雨比三维联合的Copula分布(图3)。年暴雨日数、年暴雨量和暴雨比以及年均暴雨强度、年暴雨量和暴雨比三维联合Copula分布中,最优联合函数Clayton Copula的均方根误差(RMSE)较大,其Copula拟合的有效性尚需验证。通过K-S2进行检验,返回值P分别为0.041和0.047;因此,上述2对Copula不适合用于反映本区暴雨综合概率。
图3 Copula三维联合累积概率分布
Fig.3 Cumulative probability distribution by the three-dimensional Copula function
由图3可知,多变量联合更多的是展现变量间的概率变化,如图3a中点(0.87,0.72,0.64,0.38)呈现的信息是年暴雨日数累积概率为0.87时,对应的年暴雨量和年均暴雨强度累积概率分别为0.72和0.64,此时对应的Frank Copula值为0.38;X~Y~Z数值的差异呈现暴雨各变量在累积分布中的非同步性,即1 a中出现的暴雨日数较多,却对应较少的暴雨量,此时年均暴雨强度则较低,所以在累积概率上表现为Y~Z轴的滞后性,而这种情况出现的概率为0.38。Copula联合后所包含的信息远远超过图2单一变量提供的信息,呈现的信息比单一要素更加丰富,凸显了要素间的联系,是已有研究中欠缺和暴雨研究中必须探讨的部分。将Copula函数用于联合暴雨多维要素,可以扩宽暴雨多要素联合研究方向。
Copula累积分布值随暴雨各变量边缘分布累积概率的增大而增大,符合累积概率分布的客观事实,即X~Y~Z靠近(1,1,1)时,Copula值也趋近于“1” (图3)。由于联合变量的非同步性以及Frank Copula拟合的误差,导致图3a中坐标为X~Y~Z(0.5,1,1)的附近区域Copula值趋近于“1”,属于Copula累积分布值异常偏高,但小区域的误差对整体上Copula累积分布随变量增加而变大的客观规律影响不大,且Frank Copula函数是通过RMSE和AIC检验后比较适合用于暴雨日数、暴雨量和暴雨强度三变量联合分布的函数,因此以 Frank Copula拟合上述3个变量,并作为计算重现期的依据。
给定暴雨要素单变量重现期(T),通过公式(5)求其相应的暴雨要素值;将给定重现期背景下的暴雨要素值带入表1计算相应Copula联合分布值,通过公式(6)计算三维联合重现期(Ta);利用Kendall秩计算变量间的相关系数,得知暴雨各要素两两间的相关系数均可通过0.05水平的显著性检验(表5)。
表5 暴雨各要素两两间的相关系数
Table 5 The correlation coefficient of each factor of rainstorm
| 暴雨要素 | 年暴雨次数 | 年暴雨量 | 强度 | 站总雨量比 |
|---|---|---|---|---|
| 年暴雨次数 | 1 | |||
| 年暴雨量 | 0.887** | 1 | ||
| 强度 | 0.46** | 0.452** | 1 | |
| 站总雨量比 | 0.840** | 0.917** | 0.423** | 1 |
构建变量两两联合的Copula分布,并结合公式(7)计算Copula三维联合的同现重现期T0(表6)。样本观测长度N=58,观测时段内超越某一给定样本出现的次数n取值见表6。
表6 不同维度暴雨要素重现期
Table 6 The return period of rainstorm factors in different dimension
| T(a) | D50 | P50 | I | R | D50,P50,I | D50,I,R | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (d) | n | (mm) | n | (mm) | n | (%) | n | Ta | T0 | Ta | T0 | ||||||
| 2 | 2.4 | 39 | 233.6 | 40.96 | 73.4 | 44.89 | 0.247 | 40.67 | 1.43 | 3.04 | 1.39 | 3.01 | |||||
| 5 | 3.4 | 28 | 346 | 26.19 | 84.5 | 27.42 | 0.337 | 26.85 | 3.12 | 20.45 | 3.05 | 20.09 | |||||
| 10 | 4.4 | 17 | 421.9 | 18.71 | 88 | 17.85 | 0.391 | 21.09 | 5.06 | 28.2 | 4.92 | 30.1 | |||||
| 20 | 5.3 | 11 | 493.6 | 14.01 | 99.5 | 13.49 | 0.407 | 12.39 | 6.81 | 133.15 | 6.62 | 103.27 | |||||
| 50 | 5.6 | 6.6 | 544 | 7.57 | 109 | 8.50 | 0.46 | 9.42 | 13.7 | 214.28 | 12.56 | 206.73 | |||||
| 100 | 6.3 | 6 | 629.4 | 6.30 | 116.6 | 6.13 | 0.489 | 6.57 | 33.27 | 547.19 | 31.4 | 512.97 | |||||
表6可知,2对三维Copula联合分布的联合重现期均小于单要素重现期,同现重现期都大于单要素重现期,以单变量10 a重现期为例,联合重现期大约为5 a,而同现重现期至少为28 a。随着单变量重现期的增加,同现重现期的增速远远大于联合重现期的减小速率。单变量的重现期较大时,表明此时的变量值属于该变量的极值,为少数事件,将暴雨的多个变量的极值联合在一起时,同现重现期显著延长,联合重现期明显缩短。如表6,单变量重现期为100 a时,其同现重现期则延长至547.19 a和512.97 a,而对应的联合重现期则分别缩至33.27 a和31.4 a。这种多变量联合后的重现期信息是单变量重现期无法给予的,Copula多维分布函数对于探知具有多要素的暴雨联合概率和重现期具有较强的实用性。
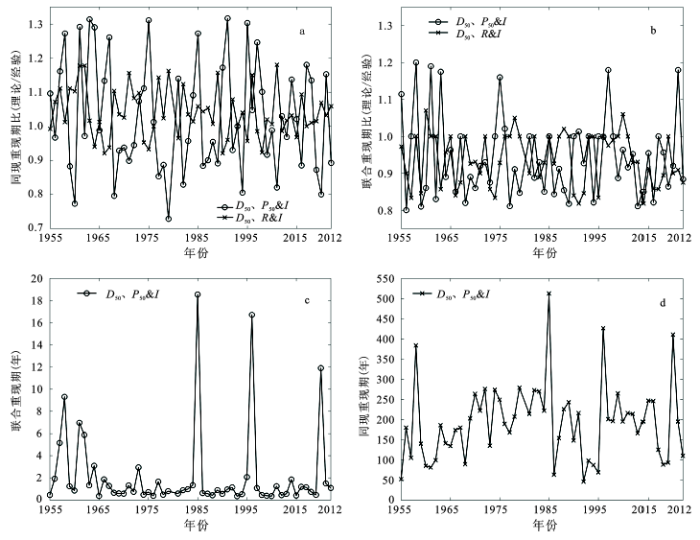
暴雨要素的多面性,使得探索能贴切反映暴雨重现特征的要素尤为重要。将上述2对三维联合的理论重现期与实际重现期进行对比(图4a,b)。图中曲线为理论重现期与实际重现期的比值,数值越趋近于1,表明理论重现期越接近于实际重现期。由图4 可知,Frank Copula联合的年暴雨日数、暴雨比和年均暴雨强度的理论重现期与实际重现期的比值波动较小,趋近于1,适合用于反映3要素的综合重现期。从表6中可知,单变量重现期只能反映单要素重现特征。组合后的重现期综合考虑了暴雨的多个要素,比单要素重现期更具可靠性。
图4 Copula重现期及理论重现期与实际重现期的比值
Fig.4 The Copula return period and the ratios of theory return period to actual return period
由图4c ,d可知,宽甸县暴雨联合重现期多为0~2 a,重现周期短,为暴雨高频区;同现重现期多在300 a以内。少数年份的重现期较长,如1958年、1985年和1996年,像1985年暴雨各要素同时偏高的情况很少见,所以无论是联合重现期还是同现重现期均较长,属于暴雨偏强年份。联合重现期最高值19 a出现于1985年,即1 a中发生9次暴雨事件、年暴雨总量超过900 mm或年均暴雨强度在100 mm以上的重现期为19 a。同现重现期最高值也出现在该年,表示1 a发生9次暴雨事件且暴雨总量超过900 mm以及暴雨比大于0.5重现周期在513 a以上。联合重现期只需某一暴雨要素超越给定值,即为重现;同现期则需所选暴雨要素同时超越各自给定值,才为同现;所以同现重现期明显长于联合重现期,尤其在暴雨偏强年份,同现重现期更长,如1985年,联合重现期为19 a,而同现重现期在513 a。此外,2种重现期变化趋势一致,具有同步效应,恰好反映了暴雨要素的不可分割性。
1) 经AIC和RMSE优度检验,Frank Copula适合用于联合本区暴雨的多个要素。年暴雨日数、暴雨比和年均暴雨强度的联合既可以反映暴雨发生的最大可能性,又可以用于暴雨情景的重塑,适合反映暴雨的联合重现特征。
2) 单变量概率拟合分布中,年均暴雨强度集中在60~120 mm,其他暴雨要素集中度不明显,分布相对均匀。
3) 宽甸县暴雨联合重现期短,多为0~2 a,属暴雨高频区,一年中通常发生4~6次暴雨,总暴雨量集中在200~500 mm,暴雨比集中在0.3~0.5。同现重现期长,多在300 a以内,少数极端年份,同现重现期可高达500 a。暴雨偏强年份,暴雨次数增多,总暴雨量可高达900 mm,暴雨比在0.5左右波动,2种重现期相应延长,具有同步性,存在一致的变化趋势,这种趋势正好体现了暴雨要素的不可分割性,而Copula三维联合可以从3个方面反映暴雨的特征,提供了分析变量间相互联系的大量信息,是单变量拟合所不具备的。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
Integrated risk zoning of drought and waterlogging disasters based on fuzzy comprehensive evaluation in Anhui Province, China [J].https://doi.org/10.1007/s11069-013-0971-9 URL Magsci [本文引用: 1] 摘要
This study presents a methodology for risk analysis, assessment, combination, and regionalization of integrated drought and waterlogging disasters in Anhui Province, which is supported by geographical information systems (GIS) and technique of natural disaster risk assessment from the viewpoints of climatology, geography, disaster science, environmental science, and so on. Along with the global warming, the occurrences of water-related disasters become more frequent and serious. It is necessary to determine the mode of spatial distribution of water-related disaster risk. Based on the principle of natural disaster risk, natural conditions, and socioeconomic situation, drought and waterlogging disaster risk index, which combined hazard, exposure, vulnerability, and restorability, was developed by using combined weights, entropy, and fuzzy comprehensive evaluation method. Drought and waterlogging disaster risk zoning map was made out by using GIS spatial analysis technique and gridding GIS technique. It was used for comparing the relative risk of economic and life losses in different grids of Anhui Province. It can also be used to compare the situation of different levels of drought and waterlogging disaster combination risk in a similar place. The result shows that the northwestern and central parts of Anhui Province possess higher risk, while the southwestern and northeastern parts possess lower risk. The information obtained from statistical offices and remote sensing data in relation to results compiled were statistically evaluated. The results obtained from this study are specifically intended to support local and national governmental agencies on water-related disaster management.
|
| [3] |
2012年4月华南地区降水异常事件及成因诊断分析 [J].
基于实时、历史观测资料和NCEP/NCAR再分析资料,采用气候统计和气候事件机理诊断分析方法,对2012年4月华南地区降水异常事件及其成因机制开展总结分析。结果表明:2012年4月华南大部地区降水异常偏多,强降水频发。华南地区降水异常事件的主要成因为:异常的高低纬环流形势配合,为华南地区降水异常偏多提供有利的环流背景,利于北方冷空气南下与西南暖湿气流在华南地区交汇;同期华南地区为异常偏强的上升气流控制,高低空辐散、辐合环流配置利于华南地区降水异常偏多;源自孟加拉湾、南海和西太平洋的异常水汽输送为华南地区提供良好的水汽条件,是华南地区降水异常事件的重要影响因子。
Abnormal Precipitation Event and Its Possible Mechanism over South China in April 2012 [J].
基于实时、历史观测资料和NCEP/NCAR再分析资料,采用气候统计和气候事件机理诊断分析方法,对2012年4月华南地区降水异常事件及其成因机制开展总结分析。结果表明:2012年4月华南大部地区降水异常偏多,强降水频发。华南地区降水异常事件的主要成因为:异常的高低纬环流形势配合,为华南地区降水异常偏多提供有利的环流背景,利于北方冷空气南下与西南暖湿气流在华南地区交汇;同期华南地区为异常偏强的上升气流控制,高低空辐散、辐合环流配置利于华南地区降水异常偏多;源自孟加拉湾、南海和西太平洋的异常水汽输送为华南地区提供良好的水汽条件,是华南地区降水异常事件的重要影响因子。
|
| [4] |
东北地区降水日数、强度和持续时间的年代际变化 [J].Decade variations of precipitation event frequency, intensity and duration in the Northeast China . |
| [5] |
我国中东部逐时雨强时空分布及重现期的估算 [J].https://doi.org/10.11821/xb201003004 URL Magsci [本文引用: 1] 摘要
基于我国1991-2005年逐小时的降水观测资料,利用概率分布、统计检验与极值分布等方法,分析研究了我国中东部地区逐时降水强度的时空分布特征及一小时最大雨强的50年、100年重现期估算等问题。结果表明:对于4mmh-1以上的较强雨强而言,出现频数最多的地区主要在我国南部沿海地区;长江以南大部地区一小时雨强的最大值为60~80mmh-1,沿海地区一小时雨强的最大值可以达到80~90mmh-1;雨强出现频数的日变化在各地区是很不相同的,西南和华南是雨强日变化最明显的地区,4mmh-1以上量级的检验结果几乎全部都超过0.01的信度要求;一小时最大雨强50、100年重现期估算值的空间分布形态具有一致性,高值区主要在东南沿海一带,50年、100年一遇的一小时雨强达80~120mmh-1、100~150mmh-1。
Temporal and spatial distributions of hourly rain intensity and recurrence periods in eastern and central China .https://doi.org/10.11821/xb201003004 URL Magsci [本文引用: 1] 摘要
基于我国1991-2005年逐小时的降水观测资料,利用概率分布、统计检验与极值分布等方法,分析研究了我国中东部地区逐时降水强度的时空分布特征及一小时最大雨强的50年、100年重现期估算等问题。结果表明:对于4mmh-1以上的较强雨强而言,出现频数最多的地区主要在我国南部沿海地区;长江以南大部地区一小时雨强的最大值为60~80mmh-1,沿海地区一小时雨强的最大值可以达到80~90mmh-1;雨强出现频数的日变化在各地区是很不相同的,西南和华南是雨强日变化最明显的地区,4mmh-1以上量级的检验结果几乎全部都超过0.01的信度要求;一小时最大雨强50、100年重现期估算值的空间分布形态具有一致性,高值区主要在东南沿海一带,50年、100年一遇的一小时雨强达80~120mmh-1、100~150mmh-1。
|
| [6] |
Community-based scenario modelling and disaster risk assessment of urban rainstorm waterlogging [J].https://doi.org/10.1007/s11442-011-0844-7 URL Magsci [本文引用: 1] 摘要
情形建模和对自然灾难的风险评价是在灾难研究的热点之一。然而,起来直到现在,城市的自然灾难风险评价缺乏普通过程和节目。这篇论文作为灾难选择暴风雨 waterlogging 研究,它是为在中国的大多数城市的最经常发生的危险之一。作为一个例子,我们使用了小规模的综合方法论在上海的 Jingan 区域估计关于暴风雨 waterlogging 危险的风险。基于灾难风险的基本概念,这篇论文使用情形建模在不同回来时期表示小规模的城市的暴风雨 waterlogging 灾难的风险。通过危险和暴露的这分析,我们模仿不同灾难情形并且为小规模的城市的暴风雨 waterlogging 灾难风险评价建议一个全面分析方法和过程。包括一个城市的地面模型,一个城市的降雨模型和一个城市的排水模型,一条基于格子的地理信息系统(GIS ) 途径被使用模仿淹没区域和深度。为居住大楼和内容的阶段损坏曲线然后被从领域调查的 waterlogging 的数据,它进一步使用了分析危险,暴露和损失评价的损失产生。最后,为灾难损坏的 exceedance 概率曲线用每个模仿的事件和各自的 exceedance 可能性的损坏被构造。一个框架也为通过 exceedance 概率曲线和年度平均 waterlogging 损失联合 waterlogging 风险,风险和管理计划被开发。这是为小规模的城市的自然灾难情形模拟和风险评价的新探索。
|
| [7] |
Copula-based frequency analysis of overflow and flooding in urban drainage systems [J].https://doi.org/10.1016/j.jhydrol.2013.12.006 URL [本文引用: 1] 摘要
The performance evaluation of urban drainage systems is essentially based on accurate characterisation of rainfall events, where a particular challenge is development of the joint distributions of dependent rainfall variables such as duration and depth. In this study, the copula method is used to separate the dependence structure of rainfall variables from their marginal distributions and the different impacts of dependence structure and marginal distributions on system performance are analysed. Three one-parameter Archimedean copulas, including Clayton, Gumbel, and Frank families, are fitted and compared for different combinations of marginal distributions that cannot be rejected by statistical tests. The fitted copulas are used, through the Monte Carlo simulation method, to generate synthetic rainfall events for system performance analysis in terms of sewer flooding and Combined Sewer Overflow (CSO) discharges. The copula method is demonstrated using an urban drainage system in the UK, and the cumulative probability distributions of maximum flood depth at critical nodes and CSO discharge volume are calculated. The results obtained in this study highlight the importance of taking into account the dependence structure of rainfall variables in the context of urban drainage system evaluation and also reveal the different impacts of dependence structure and marginal distributions on the probabilities of sewer flooding and CSO volume.
|
| [8] |
Use of a gaussian copula for multivariate extreme value analysis: Some case studies in hydrology [J].https://doi.org/10.1016/j.advwatres.2006.08.001 URL Magsci [本文引用: 1] 摘要
Risk assessment requires a description of the probabilistic properties of hydrological variables. In a number of cases, this description is made on a single variable, whereas most hydrological events are intrinsically multivariate. In this context, copulas have recently received attention in order to derive a multivariate frequency analysis. After a reminder of the general results in the field of multivariate extreme value theory, the paper gives a description of a very simple copula, the Gaussian copula. Four case studies demonstrate its usefulness in the contexts of field significance determination, regional risk analysis, discharge-duration-frequency (QdF) models with design hydrograph derivation and regional frequency analysis. The limitations and potential errors related to this statistical tool are also highlighted.
|
| [9] |
Multivariate standardized drought index: a parametric multi-index model [J].https://doi.org/10.1016/j.advwatres.2013.03.009 URL [本文引用: 1] 摘要
Defining droughts based on a single variable/index (e.g., precipitation, soil moisture, or runoff) may not be sufficient for reliable risk assessment and decision-making. In this paper, a multivariate, multi-index drought-modeling approach is proposed using the concept of copulas. The proposed model, named Multivariate Standardized Drought Index (MSDI), probabilistically combines the Standardized Precipitation Index (SPI) and the Standardized Soil Moisture Index (SSI) for drought characterization. In other words, MSDI incorporates the meteorological and agricultural drought conditions for overall characterization of drought. In this study, the proposed MSDI is utilized to characterize the drought conditions over several Climate Divisions in California and North Carolina. The MSDI-based drought analyses are then compared with SPI and SSI. The results reveal that MSDI indicates the drought onset and termination based on the combination of SPI and SSI, with onset being dominated by SPI and drought persistence being more similar to SSI behavior. Overall, the proposed MSDI is shown to be a reasonable model for combining multiple indices probabilistically.
|
| [10] |
A copula-based joint deficit index for droughts [J].https://doi.org/10.1016/j.jhydrol.2009.10.029 URL [本文引用: 1] 摘要
Current drought information is based on indices that do not capture the joint behaviors of hydrologic variables. To address this limitation, the potential of copulas in characterizing droughts from multiple variables is explored in this study. Starting from the standardized index (SI) algorithm, a modified index accounting for seasonality is proposed for precipitation and streamflow marginals. Utilizing Indiana stations with long-term observations (a minimum of 80 years for precipitation and 50 years for streamflow), the dependence structures of precipitation and streamflow marginals with various window sizes from 1- to 12-months are constructed from empirical copulas. A joint deficit index (JDI) is defined by using the distribution function of copulas. This index provides a probability-based description of the overall drought status. Not only is the proposed JDI able to reflect both emerging and prolonged droughts in a timely manner, it also allows a month-by-month drought assessment such that the required amount of precipitation for achieving normal conditions in future can be computed. The use of JDI is generalizable to other hydrologic variables as evidenced by similar drought severities gleaned from JDIs constructed separately from precipitation and streamflow data. JDI further allows the construction of an inter-variable drought index, where the entire dependence structure of precipitation and streamflow marginals is preserved.
|
| [11] |
Rainfall uncertainty in hydrological modelling: An evaluation of multiplicative error models [J].https://doi.org/10.1016/j.jhydrol.2011.01.026 URL [本文引用: 1] 摘要
This paper presents an investigation of rainfall error models used in hydrological model calibration and prediction. Traditional calibration methods assume input error to be negligible: an assumption which can lead to bias in parameter estimation and compromise model predictions. In response, a growing number of studies now specify an error model for rainfall input, usually simple in form due to both difficulties in understanding sampling errors in rainfall, and to computational constraints during parameter estimation. Such rainfall error models have not typically been validated against experimental evidence. In this study we use data from a dense gauge/radar network in the Mahurangi catchment (New Zealand) to directly evaluate the form of basic statistical rainfall error models. For this catchment, our results confirm the suitability of a multiplicative error formulation for correcting mean catchment rainfall values during high-rainfall periods (e.g., intensities over 1 mm/h); or for longer timesteps at any rainfall intensity (timestep 1 day or greater). We show that the popular lognormal multiplier distribution provides a relatively close approximation to the true error characteristics but does not capture the distribution tails, especially during heavy rainfall where input errors would have important consequences for runoff prediction. Our research highlights the dependency of rainfall error structure on the data timestep.
|
| [12] |
Uncertainty analysis of bias from satellite rainfall estimates using copula method [J].https://doi.org/10.1016/j.atmosres.2013.08.016 URL 摘要
61We develop an uncertainty model using generated ensembles of bias-adjusted SREs.61A Gaussian copula is fitted to simulate biases of 60 daily rainfall events over the study area.61The developed model is tested for 10% of studied events which are not participated in the simulations.61For three statistical indices including Bias, RMSE, and CC, the estimates of both PERSIANN and TMPA-3B42 are improved after bias adjustment.61Copula-based ensembles generating of biases is an appropriate method to uncertainty analysis of SREs.
|
| [13] |
Spatio-temporal variations of precipitation extremes in Xinjiang, China [J].https://doi.org/10.1016/j.jhydrol.2012.02.038 URL [本文引用: 1] 摘要
This study aims to study joint probabilities and changing characteristics of precipitation extremes, as well as the implications of these changes in Xinjiang. Daily rainfall data from 53 stations across Xinjiang, China, covering a period of 1957 2009 were collected. Using eight precipitation indices, probabilistic characteristics of precipitation extremes were analyzed based on Copulas. The K method was employed to select appropriate marginal probability distributions for determining quantiles, and the Akaike Information Criterion (AIC) was used to select copulas. Results indicate the following: (1) North Xinjiang is wetter than south Xinjiang; (2) More concurrent strong and weak precipitation extremes are observed in the areas along Tianshan Mountains, and in eastern parts of the Xinjiang than those in western parts of the Xinjiang; (3) After 1980, the Xinjiang region is exhibiting a wetting tendency, and the heavy precipitation extremes tend to occur more severely and frequently; and also the possibilities of concurrent strong and weak precipitation extremes altered in a distinct pattern; (4) Tianshan Mountains can be taken as the demarcation for the occurrences of floods and droughts and the risk of droughts and floods across the Xinjiang region is expected to increase.
|
| [14] |
The return period analysis of natural disasters with statistical modeling of bivariate joint probability distribution [J].https://doi.org/10.1111/j.1539-6924.2012.01838.x URL PMID: 22616629 [本文引用: 1] 摘要
Abstract New features of natural disasters have been observed over the last several years. The factors that influence the disasters formation mechanisms, regularity of occurrence and main characteristics have been revealed to be more complicated and diverse in nature than previously thought. As the uncertainty involved increases, the variables need to be examined further. This article discusses the importance and the shortage of multivariate analysis of natural disasters and presents a method to estimate the joint probability of the return periods and perform a risk analysis. Severe dust storms from 1990 to 2008 in Inner Mongolia were used as a case study to test this new methodology, as they are normal and recurring climatic phenomena on Earth. Based on the 79 investigated events and according to the dust storm definition with bivariate, the joint probability distribution of severe dust storms was established using the observed data of maximum wind speed and duration. The joint return periods of severe dust storms were calculated, and the relevant risk was analyzed according to the joint probability. The copula function is able to simulate severe dust storm disasters accurately. The joint return periods generated are closer to those observed in reality than the univariate return periods and thus have more value in severe dust storm disaster mitigation, strategy making, program design, and improvement of risk management. This research may prove useful in risk-based decision making. The exploration of multivariate analysis methods can also lay the foundation for further applications in natural disaster risk analysis.
|
| [15] |
Future joint probability behaviors of precipitation extremes across China: Spatiotemporal patterns and implications for flood and drought hazards [J].https://doi.org/10.1016/j.gloplacha.2014.11.012 URL [本文引用: 1] 摘要
Observed daily precipitation from 527 meteorology stations in China during 1960–2005, and simulated daily precipitation from five Earth System Models (ESMs) under historical, RCP2.6 and RCP8.5 scenarios from Coupled Model Intercomparison Project Phase 5 (CMIP5) datasets are analyzed to investigate joint probability behaviors of precipitation extremes in China during 2021–2050 and 2071–2100. Five joint return periods based on six extreme precipitation indices are defined. These joint return periods consider co-occurrence of extreme heavy and weak precipitation, as well as joint extreme heavy precipitation events in terms of different combinations of extreme precipitation amount, intensity, fractional contribution to annual precipitation days, and consecutive wet periods. Weather Generator Model (WGEN) is used to downscale the outputs of ESMs, and Copula is applied to construct joint probability distributions. The variations of joint return periods with 5-year marginal values (marginal values larger than their 5-year return period values respectively) and 20-year marginal values are discussed to represent changes in joint probability behaviors. Results show that: (1) during 1960–2005, spatial distributions of joint return periods with 5-year marginal values are similar to those with 20-year marginal values; (2) changes in marginal distributions and bivariate relationships between extreme indices may be the causes of joint probability distribution shift; (3) in general, during 2021–2050 and 2071–2100, there is less co-occurrence of consecutive wet and dry days, and more joint extreme heavy precipitation events with various aspects, implying less risk of co-occurrence of floods and droughts in the same year but higher risk of floods in China. But north China may face higher risk of co-occurrence of severe floods and droughts in the same year; and (4) changes in joint return periods under RCP8.5 are more remarkable than under RCP2.6. Even under RCP2.6, a scenario 202°C global average warming target is met, the changes in joint return periods are still considerable.
|
| [16] |
The joint return period analysis of natural disasters based on monitoring and statistical modeling of multidimensional hazard factors [J].https://doi.org/10.1016/j.scitotenv.2015.08.093 URL PMID: 26327640 [本文引用: 2] 摘要
As a random event, a natural disaster has the complex occurrence mechanism. The comprehensive analysis of multiple hazard factors is important in disaster risk assessment. In order to improve the accuracy of risk analysis and forecasting, the formation mechanism of a disaster should be considered in the analysis and calculation of multi-factors. Based on the consideration of the importance and deficiencies of multivariate analysis of dust storm disasters, 91 severe dust storm disasters in Inner Mongolia from 1990 to 2013 were selected as study cases in the paper. Main hazard factors from 500-hPa atmospheric circulation system, near-surface meteorological system, and underlying surface conditions were selected to simulate and calculate the multidimensional joint return periods. After comparing the simulation results with actual dust storm events in 54years, we found that the two-dimensional Frank Copula function showed the better fitting results at the lower tail of hazard factors and that three-dimensional Frank Copula function displayed the better fitting results at the middle and upper tails of hazard factors. However, for dust storm disasters with the short return period, three-dimensional joint return period simulation shows no obvious advantage. If the return period is longer than 10years, it shows significant advantages in extreme value fitting. Therefore, we suggest the multivariate analysis method may be adopted in forecasting and risk analysis of serious disasters with the longer return period, such as earthquake and tsunami. Furthermore, the exploration of this method laid the foundation for the prediction and warning of other nature disasters.
|
| [76] |
|
| [18] |
VFonctions de répartition à n dimensions et leurs marges, V Publ [J]. |
| [35] |
Erosion and Sedimentation in Drainage Basins and in Storage Reservoirs [M].
|
| [19] |
近51年宽甸旱涝年气候分析和预报 [J].Analysis and forecasting of drought and flood in Kuandian nearly 51 years [J]. |
| [20] |
东北地区降水年内分配的不均匀性 [J].https://doi.org/10.3969/j.issn.1004-4574.2009.02.014 URL [本文引用: 1] 摘要
利用东北地区93个台站1961-2005年的逐日降水资料,通 过降水集中度和降水集中期,讨论了该地区降水的年内分配不均匀分布特征.结果表明,东北地区的降水集中度自东南向西北逐渐递减;集中期具有南北高中问低的 变化特点.从长期趋势上看,降水集中度的减小趋势显著,在该地区的东北部和西北部各有一个趋势明显的区域(通过0.05的显著性检验),但集中期的减小趋 势不显著,只有2个台站通过显著性检验.年降水量与降水集中度和降水集中期的相关系数表明:东北地区年降水量与降水集中度呈显著的正相关,即年降水量越多 (少)的地区,年内降水越集中(均匀);年降水量与降水集中期的关系并不显著.
Intra-annual inhomogeneity characteristics of precipitation in Northeast China [J].https://doi.org/10.3969/j.issn.1004-4574.2009.02.014 URL [本文引用: 1] 摘要
利用东北地区93个台站1961-2005年的逐日降水资料,通 过降水集中度和降水集中期,讨论了该地区降水的年内分配不均匀分布特征.结果表明,东北地区的降水集中度自东南向西北逐渐递减;集中期具有南北高中问低的 变化特点.从长期趋势上看,降水集中度的减小趋势显著,在该地区的东北部和西北部各有一个趋势明显的区域(通过0.05的显著性检验),但集中期的减小趋 势不显著,只有2个台站通过显著性检验.年降水量与降水集中度和降水集中期的相关系数表明:东北地区年降水量与降水集中度呈显著的正相关,即年降水量越多 (少)的地区,年内降水越集中(均匀);年降水量与降水集中期的关系并不显著.
|

/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}