李欣 , 孟德友
, 孟德友
Li Xin, Meng Deyou
中图分类号: K909
文献标识码: A
文章编号: 1000-0690(2017)02-0209-08
收稿日期: 2016-02-25
修回日期: 2016-08-5
网络出版日期: 2017-02-25
版权声明: 2017 《地理科学》编辑部 本文是开放获取期刊文献,在以下情况下可以自由使用:学术研究、学术交流、科研教学等,但不允许用于商业目的.
基金资助:
作者简介:
作者简介:李欣(1981-),男,河南郑州人,博士,讲师,主要从事地理信息系统理论研究与实践应用研究。E-mail:lixin992319@163.com
展开
摘要
针对城市道路拥堵问题的日益加剧的问题,智能化城市交通管理平台是缓解拥堵问题的有效方法,利用交通流大数据预测结果进行交通诱导,能够指导用户调整出行方案,有效缓解交通压力。研究了交通流大数据的分布式增量聚合方法,对海量交通流数据进行清洗统计,为交通流预测提供数据基础,基于交通流在路网中上下游路段的相关性分析,利用路口转弯率多阶分配将该相关性量化,构建基于路网相关性的空间权重矩阵,完成对于STARIMA模型的改进。通过应用试验证明,该方法能更准确的进行交通流预测,为交通诱导信息发布提供依据。
关键词:
Abstract
Along with the accelerating urbanization, there are more and more contradictions between the number of cars and urban transportation facilities. The congestion time and congested roads in cities are increasing. Intelligent urban traffic management platform is the effective method to alleviate the increasingly serious urban congestion problems. By using prediction results of traffic flow big data, the platform can guide users to adjust the travel plan, and ease the traffic pressure effectively. How to use a large number of spatio-temporal data related to traffic activities to predict the traffic flow is the key to realizing traffic guidance. In this article, a distributed incremental aggregation method for traffic flow data is studied. The method combines the distributed incremental data aggregation method with the traffic flow data cleaning rules, makes cleaning and counting of traffic flow big data, and provides data for traffic flow forecast. With the analysis of traffic flow correlation in the network of upstream and downstream, this article uses the multi-order of turning rate in the intersection to quantize the correlation, builds the spatial weight matrix based on the road network correlation, and improves the STARIMA model. In this article, two groups of contrast experiments were made. Through the contrast experiment between MapReduce method and MPI method, the result proves that the method proposed in this article is better than the MPI method in the development cycle and stable operation. The method’s efficiency can meet the need of traffic flow data aggregation. The traffic flow statistics can be used as the basis of traffic flow forecasting. Through the contrast experiment between the Improved STARIMA model and the Dynamic STARIMA model, the result proves that the Improved STARIMA model, which considers the multi-order correlation between the upstream and downstream sections, matches the distribution rules of traffic flow in road network better. Therefore, the forecast results are more accurate. In conclusion, the method of this article is a new method of traffic flow forecasting in the background of big data, and it can realize accurate prediction.
Keywords:
中国的城市化进程正在不断加速,汽车数量增长和城市交通基础设施不足的矛盾日益突出,智能化城市交通管理平台是缓解拥堵问题的有效方法,通过大数据挖掘进行交通流预测和诱导,能够指导用户调整出行方案,有效缓解交通压力。如何利用反映交通活动的大量与时空位置相关的数据[1]进行交通流预测是实现交通诱导的关键问题。
目前国内外已经产生了很多研究成果。在大数据聚合方法方面,如增量并行数据挖掘方法[2],增量降维时序数据处理方法[3],基于MapReduce的样本抽样放回方法[4],基于MapReduce分布内存加速方法[5]等。上述方法的主要特点是通过抽样降维方式减少数据量提高效率,或基于传统规模数据集进行增量挖掘运算,或基于昂贵内存硬件提高计算性能。而针对广域网环境下不断海量增长的时空数据,以上方法仍然无法有效利用已有设备和使用较低成本解决效率问题。在交通流预测分析应用方面,主要研究成果包括历史平均模型[6]、状态空间模型[7]、时间序列模型[8]、神经网络模型[9,10]等。乐阳[11]提出基于时空依赖性的Kalman滤波模型,Kamarianakis等人[12]在交通流预测中引入时空自回归移动平均模型[13]模型,之后国内的一些学者[14~18]在此基础上进行了进一步改进,取得了较好效果。以上研究针对的是固定时段交通流数据的预测,有的仅考虑了单点交通流预测,有的对于交通流的相关性限制较多,未能真实准确的反应交通流在路网中的实际规律,还需要进行深入研究。
本文拟从交通网的时空相关性分析出发,在已有研究成果基础上,改进大数据环境下的城市交通流预测分析模型,利用河南智能交通综合管理平台获取的交通流数据,进行实验性预测分析,为下一步的实际应用提供参考依据。
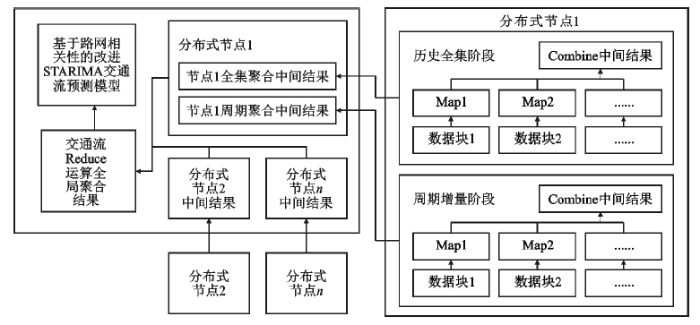
本文研究实现了一种交通流大数据分布式增量聚合管理方法,该方法将网络中的节点分为中心节点和分布节点:分布节点负责收集和处理交通路网中的不同种类传感器获取的交通流数据,定时将聚合处理完毕的数据推送到中心节点;中心节点负责对历史全集和增量阶段的交通流数据进行存储管理,执行基于路网相关性的交通流预测。图1为交通流大数据分布式增量聚合原理图。
整个数据聚合和预测过程,按照时间间隔分为多个周期阶段持续执行。第一阶段,是初次数据聚合和预测分析阶段,称作历史全集数据聚合阶段,基于网络中所有节点的数据全集进行分布式聚合运算,数据整合到中心节点后进行预测分析;后期阶段,称作周期增量数据聚合阶段,基于系统运行周期新产生的增量数据进行聚合运算,增量数据可以用来修正上一阶段预测结果。整个过程通过MapReduce模型执行,其中分布节点的Map运算包含了数据筛选清洗算法,同时在分布节点由Combine运算完成中间统计数据集处理,之后将中间结果推送到中心节点,最终在中心节点使用Reduce运算进行全局数据聚合,最终执行预测模型生成预测结果。
图1 交通流大数据分布式增量聚合原理
Fig.1 Distributed incremental aggregation principle of traffic flow big data
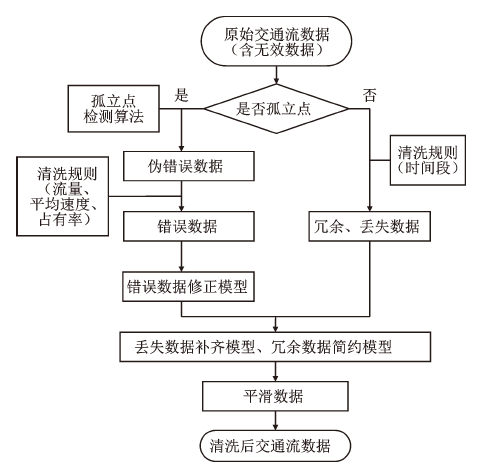
在数据聚合过程中,最为关键的是交通流数据清洗规则,国内外学者经过研究虽然取得了一定的成果[19~22],但对于复杂的交通流传感器数据,目前还没有统一的清洗规则。
本文利用文献[22]的高维交通流孤立点检测算法,以及依据阈值理论和交通流理论制定的清洗规则,对系统分布节点中的数据集进行数据清洗,步骤如图2。经过实验,通过在分布节点进行交通流数据清洗,可以纠正或丢弃错误、冗余数据90%以上,可以在较大程度上提高数据质量,进而辅助进行精准预测。在进行数据清洗的同时,由于需要对每一条数据记录进行分析,因此在清洗同时即可完成对交通路网中路段流量的统计,并传送到中心节点完成交通流预测。
城市道路网错综复杂,但根据其拓扑结构可以看出,任意两条路段之间的关系存在两种情况:一种是两条路段邻接,即两路段由某个路口相连;另一种是两条路段非邻接,即路段非首尾相连,必须通过一条或多条其他路段和路口相连。
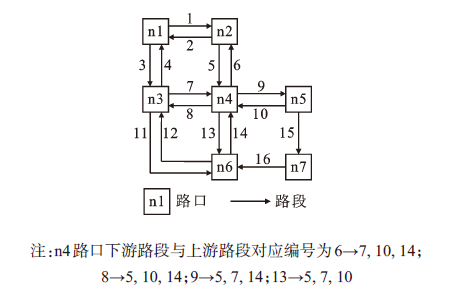
对于邻接路段,上游交通流在到达路口后会重新分配至下游路段,例如典型的十字路口车辆存在直行、左转、右转3种情况。因此,邻接路段交通流之间的关系即为上游交通流的重分配关系。图3为交通路口上下游交通流示意图。
图3 交通路口上下游交通流
Fig.3 Traffic flow upstream and downstream in the intersection n4
由图3中路段上下游关系,可以将邻接路段,第
非邻接路段中的交通流重分配可以看做是上游路段到下游路段的多阶重分配,而分配过程涉及到路径选择问题。文献[14]中分析了上游路段和下游路段在分配交通流时存在3种关系。而在实际情况下,影响驾驶员路径选择的原因比较多,例如最短距离,最短时间,个人喜好,中途点选择等等。本文仅考虑正常状态下的交通流预测问题,即驾驶员一般选择最短路径作为驾驶路线,此时上游路段A到下游路段B之间仅有唯一路径,交通流重分配仅在此路径中实现。
在非邻接路段条件下,上游路段段
式中,
通过公式(1)和(2)可以看出,上游路段的交通流会依次分配至下游路段,而下游路段被分配的流量为上游多阶路段累积分配的结果。随着经过路口数量的增加,阶数随之增加,上游路段分配至下游的流量越来越少,其时空相关性也越来越小。根据经验,2阶以内的上游路段和某下游路段的相关性较大,而3阶以上的上游路段与下游路段的相关性已经较小,可以忽略不计。
2.2.1 改进STARIMA空间权重矩阵
通过分析交通流在路网中的相关性,得到的结论是路网中路段相关性随着上下游阶数增加而减小。本文根据此结论,设计了时空自回归移动平均模型STARIMA(Space-time Autoregressive Integrated Moving Average)模型中的空间权重矩阵,并进行交通流预测。
时空自回归移动平均模型STARIMA是Pfeifer和Deutsch[23~25]提出的,公式如下:
式中,
公式中的
因此,可以将该矩阵作为空间权重矩阵进行赋值,而赋值时不仅需要考虑某路段历史和当前交通流量,还需要考虑其上游路段的历史和当前交通流量,而且上游路段距离该路段越近,其相关性和对流量预测的影响就越大,
考虑文献[23]对于
式中,
公式(4)不但反映了上下游路段在交通流重分配过程中的相关性影响,而且也考虑了两者之间的空间拓扑关系,同时还满足文献[23]提出的3种条件。因此,可以作为新的确定空间权重矩阵元素的方法应用到交通流预测分析中。
2.2.2 模型应用步骤
基于路网相关性的改进STARIMA交通流预测模型,其应用步骤可以分为以下6步:① 交通路网拓扑抽象化。根据城市路网的空间拓扑关系,将其抽象为明确表示上下游关系的网状结构,网络中包含方向和长度数据,以此为基础可以建立空间权重矩阵;② 确定空间权重矩阵元素。利用文献[26]中的交通路口动态转弯率预测模型进行估计,使用公式(4)确定一阶和二阶空间权重矩阵,而三阶以上的由于相关性较小,可以忽略不计;③ 时间序列平稳化。实际情况下,交通流时间序列为非平稳序列,可以使用序列图[10]通过差分方式使交通流时间序列平稳化;④ 确定模型阶数和参数。可以使用时空自相关函数[27]与时空偏相关函数[28]确定自回归移动平均阶数,然后利用预测值和实际值残差平方进行参数估计;⑤ 模型校验和诊断。检查预测值和实际值之间的误差序列是否满足随机误差,并检查参数估计的统计显著性,若不满足要求则返回上一步;⑥ 交通流预测。确定模型阶数和参数之后,即可将交通流历史和增量数据代入模型进行预测。
本文实验基于智能交通综合管理平台搭建,该平台提供了城市交通指挥系统、智能交通诱导系统、联网视频监控系统、智能交通检测系统等一整套综合管理平台。目前,已经在郑州、开封、洛阳等城市实现了部分应用。
郑州市动态交通流信息采集传感器,包括微波检测器、视频检测器、地磁检测器采集以及浮动车GPS数据。平台数据总量已达到160多亿条,日均增量约2 000万条。本文选取2015年11月9日至11月22日共计14 d的数据进行实验。
实验环境中架设了1台服务器作为中心节点进行交通流预测分析,4台服务器作为分布节点处理增量交通流数据,配置均为Intel5620 2.4GHz,6核,4GB内存,2TB硬盘。
实验设定初始状态下历史交通流数据集合为前4 d的交通流量数据约8 000万条,以15 min为增量周期,每一周期内的数据量约为20万条。由于白天和晚上交通流数据分布不均匀,因此在一个流量高峰周期的数据量可能达到平均量的2倍,即40万条,而且交通流数据是在不断连续增长的,必须在周期时限内完成对数据的快速聚合处理,才能满足中心节点的预测分析的需求。
本文采用了两种方法进行交通流大数据的聚合实验,并对其结果进行了比较:
1) 基于MPI的数据聚合。MPI主从模式并行程序中,主进程负责分配任务和数据,从进程完成任务后返回结果。实验利用文献[29]中的MPI方法,主进程设置在中心节点,在4台分布节点设置4个从进程,从进程中运行的计算主要是对于数据的遍历和清洗算法,在遍历数据同时完成交通网络中流量统计,并传送给中心节点的主进程,最终由主进程完成交通流预测。
2) 基于分布式增量MapReduce的数据聚合。分布节点的4台服务器存储时空数据全集,并对数据集合进行平均分块,配置48个Map运算和4个Combine运算,在Map运算中包含了交通流清洗算法,由分布节点Combine运算完成中间统计数据集处理,之后将中间结果推送到中心节点,最终在中心节点使用Reduce运算进行全局数据聚合,最终执行预测模型生成预测结果。
针对两种方法,实验选用2万、5万、10万、20万、50万和100万条数据进行聚合,并比较了两种方法的运行效率。实验结果如图4所示。
图4 两种算法不同数据量时间对比
Fig.4 The cost of time of two kinds of algorithm for different amount of data
对比两种方法可以看出,在数据量较小时,MPI方法效率要明显高于MapReduce方法,这是因为MapReduce方法包含了很多应用架构逻辑,应用逻辑会消耗一定的时间;而在数据量不断增大之后,数据量成为时间消耗的主导因素,应用架构逻辑所占用的时间所占比例越来越小,两者处理数据的时间不断接近,而在数据量达到50万条时,MapReduce方法所用时间反而少于MPI方法,而随着数据量的进一步增加,MapReduce的优势将更加明显。而且两种方法虽然耗费时间的数量级仍然一样,但MapReduce的快速开发周期和连续稳定的运行效果是MPI方法无法达到的。总体上看,实验使用的分布式增量交通流大数据聚合方法,从开发周期和运行效率上都可以满足城市交通预测分析的需要。
交通流统计数据集中传送到中心节点后,即可使用基于路网相关性的改进STARIMA模型进行交通流预测。按照模型应用步骤,首先构建交通路网拓扑结构,对研究区域进行抽象化,图5a为郑州市城区道路交通网,图5b是对图5a中矩形框范围内龙子湖高校园区路网抽象化结果示意图。
图5 郑州市城区道路交通网及龙子湖高校园区路网抽象化结果
Fig.5 Zhengzhou City road network and abstraction of Longzi Lake college area road network
根据文献[30]的研究发现,交通流预测周期以15 min为宜,若时间间隔过小,交通流数据会被信号灯或其他因素影响而出现较大波动,而时间间隔过大,对于交通流预测又无法起到实际的诱导交通作用。因此本文使用15 min作为数据增量周期进行预测。
对于交通流预测,本文也使用了两种方法进行对比试验:
1) 动态STARIMA预测模型。文献[12]中提出了该模型,该模型将上下游路段的相关性引入STARIMA模型,但只考虑了一阶上游路段的影响。
2) 基于路网相关性的改进STARIMA模型。本文提出的模型不仅引入路网之间的相关性,而且将n阶上游路段的影响考虑在内。
以图5b中的示意路段为例,将实验数据中的前4 d数据作为历史数据,使用两种预测模型对后10 d的数据做预测。每天24 h按照15 min一个周期进行划分,一天分为96个时段,所以共使用384个时段的历史数据预测后960个时段的交通流量,将预测结果和实际交通流数据对比,计算均方误差作为预测误差指标,两种方法得到的预测误差结果如表1。
表1 两种方法预测结果均方误差(MSE)对比
Table 1 The MSE comparison of two predict methods results
| 编号 | 动态 STARIMA | 路网相关STARIMA | 编号 | 动态 STARIMA | 路网相关STARIMA | 编号 | 动态 STARIMA | 路网相关STARIMA |
|---|---|---|---|---|---|---|---|---|
| 1 | 8638.27 | 6643.68 | 22 | 3338.29 | 2839.48 | 43 | 3977.67 | 3058.83 |
| 2 | 7396.01 | 6032.39 | 23 | 6236.77 | 5064.66 | 44 | 4458.98 | 3847.45 |
| 3 | 6631.31 | 4983.57 | 24 | 7784.39 | 5338.54 | 45 | 8979.37 | 7432.82 |
| 4 | 8362.58 | 5986.44 | 25 | 2526.67 | 1438.33 | 46 | 8443.69 | 6234.73 |
| 5 | 2948.21 | 1863.49 | 26 | 3464.32 | 1974.34 | 47 | 2798.55 | 1846.49 |
| 6 | 4820.22 | 2799.35 | 27 | 8764.39 | 5890.43 | 48 | 3985.42 | 2275.45 |
| 7 | 9230.23 | 7390.32 | 28 | 6549.48 | 5438.93 | 49 | 7849.43 | 5893.37 |
| 8 | 7857.46 | 6074.45 | 29 | 12974.45 | 8865.29 | 50 | 6692.38 | 5624.78 |
| 9 | 15324.01 | 12984.61 | 30 | 13084.44 | 10474.63 | 51 | 6639.32 | 4542.43 |
| 10 | 11479.46 | 8753.05 | 31 | 5478.34 | 3740.35 | 52 | 5873.57 | 4147.57 |
| 11 | 3892.27 | 2775.73 | 32 | 4858.34 | 3275.39 | 53 | 3720.32 | 2475.54 |
| 12 | 4917.48 | 3295.48 | 33 | 7434.95 | 6578.36 | 54 | 3920.28 | 2143.27 |
| 13 | 3729.33 | 2903.57 | 34 | 7868.23 | 5920.49 | 55 | 2039.58 | 1343.47 |
| 14 | 3928.23 | 2638.57 | 35 | 6743.23 | 4839.33 | 56 | 3235.62 | 1634.57 |
| 15 | 4478.19 | 3902.29 | 36 | 7820.33 | 5923.67 | 57 | 4838.88 | 3822.44 |
| 16 | 6903.36 | 4632.84 | 37 | 8068.35 | 6488.38 | 58 | 5749.23 | 4727.28 |
| 17 | 10573.48 | 7296.23 | 38 | 7819.28 | 6367.35 | 59 | 6403.45 | 4884.74 |
| 18 | 9033.54 | 7018.83 | 39 | 3894.22 | 2057.75 | 60 | 6653.63 | 4954.54 |
| 19 | 4847.34 | 3892.33 | 40 | 4780.44 | 3628.65 | 61 | 7570.49 | 6343.45 |
| 20 | 3309.21 | 3087.88 | 41 | 7897.36 | 4929.38 | 62 | 8788.48 | 6932.43 |
| 21 | 5789.22 | 4274.49 | 42 | 8902.34 | 5563.37 |
对比两种方法的实验结果可以看出,基于路网相关性的改进STARIMA方法预测效果要明显优于动态 STARIMA方法,原因在于动态STARIMA方法仅考虑了一阶上下游路段之间的相关性,而本文提出的方法还考虑了二阶以上上下游路段之间的相关性,因此更加符合道路网中交通流的分配规则,预测结果也更加准确。
本文设计了交通流大数据分布式增量聚合管理方法,创新点在于将分布式增量数据聚合方法和交通流数据清洗规则相结合,对海量交通流数据进行聚合管理,通过MPI和MapReduce两种方法的对比试验,证明本文提出的方法在开发周期和稳定运行效果上要优于MPI方法,运行效率上能够满足交通流大数据聚合的需要,最终得到的交通流统计数据可以作为交通流预测的数据基础。而本文设计的大数据环境下基于路网相关性的改进STARIMA模型,创新点在于利用路口转弯率多阶分配将交通流在路网中上下游路段的相关性量化,以此为基础构建了空间权重矩阵,完成对于STARIMA模型的改进,通过对比试验,证明预测结果优于仅考虑一阶相关性的动态STARIMA模型,可以为诱导交通信息发布提供依据。
本文的预测模型在路径选择问题方面仅考虑了最短路径情况,而未考虑实际行车过程中最短时间,中途点选择等问题,还应在下一步的工作中展开研究。
The authors have declared that no competing interests exist.
| [1] |
论时空大数据及其应用 [J].
时空大数据与非空间数据相比,具有空间性、时间性、多维性、海量性、复杂性等特点,其云计算方法和挖掘技术是目前国际遥感科学技术的前沿领域之一。本文围绕遥感大数据的特点、时空大数据云计算和遥感大数据挖掘等关键问题,深入探讨了时空大数据的研究进展及应用,并展望了时空大数据的发展前景。
The theory of space-time big data and its application.
时空大数据与非空间数据相比,具有空间性、时间性、多维性、海量性、复杂性等特点,其云计算方法和挖掘技术是目前国际遥感科学技术的前沿领域之一。本文围绕遥感大数据的特点、时空大数据云计算和遥感大数据挖掘等关键问题,深入探讨了时空大数据的研究进展及应用,并展望了时空大数据的发展前景。
|
| [2] |
Beyond online aggregation: Parallel and incremental data mining with online Map-Reduce [M] |
| [3] |
Incremental clustering of time-series by fuzzy clustering.
Today, analyzing the user's behavior has gained wide importance in the data mining community. Typically, the behavior of a user is defined as a time series of his or her activities. In this paper, users are clustered based upon time series extracted from their behavior during the interaction with given system. Although there are several different techniques used to cluster time series and sequences, this paper will attack the problem by utilizing a novel incremental fuzzy clustering strategy in order to achieve the objective. Upon dimensionality reduction, time series data are pre-clustered using the longest common subsequence as an indicator for similarity measurement. Afterwards, by utilizing an efficient method, clusters are updated incrementally and periodically through a set of fuzzy approaches. In addition, we will present the benefits of the proposed system by implementing a real application: Customer Segmentation. In addition to having a low complexity, this approach can provide a deeper and more unique perspective for clustering of time series.
|
| [4] |
Very fast estimation for result and accuracy of big data analysis:The EARL system [M] |
| [5] |
Accelerating MapReduce with Distributed Memory Cache [M] |
| [6] |
Improved estimation of traffic flow for real-time control [M] |
| [7] |
Dynamic prediction of traffic volume through Kalman filtering theory [J].https://doi.org/10.1016/0191-2615(84)90002-X URL [本文引用: 1] 摘要
Two models employing Kalman filtering theory are proposed for predicting short-term traffic volume. Prediction parameters are improved using the most recent prediction error and better volume prediction on a link is achieved by taking into account data from a number of links. Based on data collected from a street network in Nagoya City, average prediction error is found to be less than 9% and maximum error less than 30%. The new models perform substantially (up to 80%) better than UTCS-2.
|
| [8] |
Analysis of freeway traffic time-series data by using Box-Jenkins technique [M]// |
| [9] |
Short-term inter-urban traffic forecasts using neural networks [J].https://doi.org/10.1016/S0169-2070(96)00697-8 URL [本文引用: 1] 摘要
This paper reports on a study in which backpropagation neural networks were trained to make short-term forecasts of traffic flow, speed and occupancy in The Netherlands. In order to overcome the problem of the multitude of possible input parameters, a technique of stepwise reduction of network size was developed by elasticity testing the large neural networks. Results for occupancy and flow forecasts by this method show some promise. Forecasts of vehicle speed were much less successful. The elasticity tests were found to be useful, for both enabling network size reduction and as a means of interpreting the neural network model.
|
| [10] |
An urban traffic flow model integrating neural networks [J].https://doi.org/10.1016/S0968-090X(97)00015-6 URL [本文引用: 2] 摘要
Abstract Over the past few years, artificial intelligence techniques have played important roles in the design of sophisticated traffic management systems. In this paper, we propose a cooperation based neural networks traffic flow model, which aims at being integrated into a real time adaptive urban traffic control system. The modelling is separated into two steps. Firstly, the traffic flow is modelled on a single signalized link by a local neural network. Secondly, based on communications between local neural networks, the traffic flow is modelled over a wide network of junctions. Based on simulated data, the paper concludes on the potentials of neural networks applied to traffic flow modelling. One minute ahead predictions of the queue lengths and the output flows have been obtained with fairly good accuracy. Nevertheless, it emphasizes the real need to further investigate these techniques on experimental data.
|
| [11] |
Spatial-temporal dependency of traffic flow and its implications for short-term traffic forecasting[D]. |
| [12] |
Space-time modeling of traffic flow [J].https://doi.org/10.1016/j.cageo.2004.05.012 URL [本文引用: 1] 摘要
This paper discusses the application of space-time autoregressive integrated moving average (STARIMA) methodology for representing traffic flow patterns. Traffic flow data are in the form of spatial time series and are collected at specific locations at constant intervals of time. Important spatial characteristics of the space-time process are incorporated in the STARIMA model through the use of weighting matrices estimated on the basis of the distances among the various locations where data are collected. These matrices distinguish the space-time approach from the vector autoregressive moving average (VARMA) methodology and enable the model builders to control the number of the parameters that have to be estimated. The proposed models can be used for short-term forecasting of space-time stationary traffic-flow processes and for assessing the impact of traffic-flow changes on other parts of the network. The three-stage iterative space-time model building procedure is illustrated using 7.5 min average traffic flow data for a set of 25 loop-detectors located at roads that direct to the centre of the city of Athens, Greece. Data for two months with different traffic-flow characteristics are modelled in order to determine the stability of the parameter estimation.
|
| [13] |
The identification of regional forecasting models using space-time correlation functions [J].https://doi.org/10.2307/621623 URL [本文引用: 1] 摘要
Two broad classes of aggregate regional forecasting model are defined: autoprojective models belonging to the general family of space-time autoregressive-moving average processes, and explanatory (including leading indicator) models that constitute the class of space-time regression or transfer function processes. A procedure based on the estimation of space-time correlation functions is developed for identifying (selecting) operational models from these classes. For a given body of data, both the degree of non-stationarity and the type and order of representative model can be decided by studying the shape of the appropriate correlation functions. Using artificial and actual data series, the procedure is shown to perform well. The space-time autocorrelation functions give a clear indication of the sort of autoprojective process generating the data. Although less straightforward and often requiring data pre-whitening, the space-time cross-correlation function appears to be quite successful in identifying explanatory (transfer function) models that are plausible approximations to the dynamic relationships underlying the observed series.
|
| [14] |
基于时空模型的道路网交通状态预测 [M]Traffic state forecast of road network based on space-time model//Proceedings of the Fourth China Annual Conference on ITS. |
| [15] |
The application of space-time ARIMA model On traffic flow forecasting [M]
|
| [16] |
Chen Qi et al. Short-term traffic flow forecasting of urban network based on dynamic STARIMA model [M]
|
| [17] |
基于动态交通流分配参数的网络交通状态建模与分析 [D].
Modeling and analyzing the network-level traffic status based on dynamic traffic assignment ratios.
|
| [18] |
区域交通状态分析的时空分层模型 [J].https://doi.org/10.3321/j.issn:1000-0054.2007.01.042 URL [本文引用: 1] 摘要
为了解决区域交通状态分析问题,提出了一种区域交通状态时空分层模型及其建立方法。根据区域交通状态分析需求,设定交通拥堵的不同截值,把路口状态划分为不同层次,建立了时空分层模型。该模型含盖了交通网络的微观、中观和宏观交通参数,包含交通网络时空信息和交通状态信息,得到路口可达性和路段连通性的分析结果,解决了目前区域交通状态自动分析中模型建立问题。仿真结果表明:分层模型能够把路网中不同交通状态的路口分离为具有不同可达性的层次,能够从中分析出路口可达性、路段连通性和路网交通状态的变化,并能够直接表示时空状态信息。该建模方法和分析方法可以直接用于交通状态的自动分析中,所提出分层模型也可用到交通诱导和交通控制中。
Spatial-temporal hierarchical model for area traffic state analysis. Journal of Tsinghua University: https://doi.org/10.3321/j.issn:1000-0054.2007.01.042 URL [本文引用: 1] 摘要
为了解决区域交通状态分析问题,提出了一种区域交通状态时空分层模型及其建立方法。根据区域交通状态分析需求,设定交通拥堵的不同截值,把路口状态划分为不同层次,建立了时空分层模型。该模型含盖了交通网络的微观、中观和宏观交通参数,包含交通网络时空信息和交通状态信息,得到路口可达性和路段连通性的分析结果,解决了目前区域交通状态自动分析中模型建立问题。仿真结果表明:分层模型能够把路网中不同交通状态的路口分离为具有不同可达性的层次,能够从中分析出路口可达性、路段连通性和路网交通状态的变化,并能够直接表示时空状态信息。该建模方法和分析方法可以直接用于交通状态的自动分析中,所提出分层模型也可用到交通诱导和交通控制中。
|
| [19] |
交通流信息挖掘的非参数概率变点模型研究 [J].https://doi.org/10.3963/j.issn.1006-2823.2010.04.039 URL [本文引用: 1] 摘要
交通流状态辨识是智能运输系统(ITS),尤其是其先进的交通管理系统(ATMS)和先进的出行者信息系统(ATIS)研究的一个重要内容.以往算法主要集中在交通流预辨识(即交通流预测)和交通流实时辨识(即事件检测或交通流突变检测)的研究上,而忽略对交通流关键参数量变模式的辨认.依据交通流理论,结合非参数变点统计方法,以在淄博市人民路上采获的拥挤车流数据的研究为例,建立对交通模式量变识别的非线性概率变点模型,对变点存在与否进行假设检验,并对变点(时间)位置的搜索算法作了研究.结合实地数据对本方法进行了标定和检验,验证了本方法的有效性和可行性.
Study on Nonparametric Probability Change-point Model for Traffic Flow Exploitation. https://doi.org/10.3963/j.issn.1006-2823.2010.04.039 URL [本文引用: 1] 摘要
交通流状态辨识是智能运输系统(ITS),尤其是其先进的交通管理系统(ATMS)和先进的出行者信息系统(ATIS)研究的一个重要内容.以往算法主要集中在交通流预辨识(即交通流预测)和交通流实时辨识(即事件检测或交通流突变检测)的研究上,而忽略对交通流关键参数量变模式的辨认.依据交通流理论,结合非参数变点统计方法,以在淄博市人民路上采获的拥挤车流数据的研究为例,建立对交通模式量变识别的非线性概率变点模型,对变点存在与否进行假设检验,并对变点(时间)位置的搜索算法作了研究.结合实地数据对本方法进行了标定和检验,验证了本方法的有效性和可行性.
|
| [20] |
数据质量和数据清洗研究综述 [J].URL 摘要
对数据质量,尤其是数据清洗的研究进行了综述。首先说明数据质量的重要性和衡量指标,定义了数据清洗问题。然后对数据清洗问题进行分类,并分析了解决这些问题的途径。最后说明数据清洗研究与其他技术的结合情况,分析了几种数据清洗框架。最后对将来数据清洗领域的研究问题作了展望。
Research on Data Quality and Data Cleaning: A Survey. URL 摘要
对数据质量,尤其是数据清洗的研究进行了综述。首先说明数据质量的重要性和衡量指标,定义了数据清洗问题。然后对数据清洗问题进行分类,并分析了解决这些问题的途径。最后说明数据清洗研究与其他技术的结合情况,分析了几种数据清洗框架。最后对将来数据清洗领域的研究问题作了展望。
|
| [21] |
基于非线性组合模型的交通流预测方法 [J].Magsci 摘要
为开发智能交通系统,提出一种基于RBF和ARIMA网络非线性组合模型的短时交通流预测方法,采用三层结构的RBF网络将2种单一预测方法——RBF和ARIMA网络进行非线性组合,利用实测数据对3类方法进行仿真实验,结果表明,非线性组合模型的预测准确性高于各自单独使用时的准确性,组合模型发挥了2种单一方法各自的优势,是短时交通流预测的有效方法。
Traffic Flow Prediction Method Based on Non-linear Hybrid Model [J].Magsci 摘要
为开发智能交通系统,提出一种基于RBF和ARIMA网络非线性组合模型的短时交通流预测方法,采用三层结构的RBF网络将2种单一预测方法——RBF和ARIMA网络进行非线性组合,利用实测数据对3类方法进行仿真实验,结果表明,非线性组合模型的预测准确性高于各自单独使用时的准确性,组合模型发挥了2种单一方法各自的优势,是短时交通流预测的有效方法。
|
| [22] |
交通流数据清洗规则研究 [J].https://doi.org/10.3969/j.issn.1000-3428.2011.20.066 Magsci [本文引用: 1] 摘要
交通检测器获得的数据存在无效、冗余、错误、时间点漂移及丢失等质量问题。为此,在分析影响数据质量问题原因的基础上,给出交通流数据清洗的概念,研究“脏数据”的清洗规则与清洗步骤,并对环形线圈检测器检测到的数据进行验证。结果表明,该清洗规则对错误、丢失、冗余等“脏数据”的识别率均在90%以上。
Research on Traffic Flow Data Cleaning Rules. https://doi.org/10.3969/j.issn.1000-3428.2011.20.066 Magsci [本文引用: 1] 摘要
交通检测器获得的数据存在无效、冗余、错误、时间点漂移及丢失等质量问题。为此,在分析影响数据质量问题原因的基础上,给出交通流数据清洗的概念,研究“脏数据”的清洗规则与清洗步骤,并对环形线圈检测器检测到的数据进行验证。结果表明,该清洗规则对错误、丢失、冗余等“脏数据”的识别率均在90%以上。
|
| [23] |
A three-stage iterative procedure for space-time modeling [J].https://doi.org/10.1080/00401706.1980.10486099 URL [本文引用: 1] 摘要
Abstract A three-stage iterative procedure for building space-time models is presented. These models fall into the general class of STARIMA models and are characterized by autoregressive and moving average terms lagged in both time and space. This model class collapses into the ARIMA model class in the absence of spatial correlation. The theoretical properties of STARIMA models are presented and the model building procedure is described and illustrated by a substantive example.
|
| [24] |
Identification and interpretation of first-order space-time ARMA models [J].https://doi.org/10.1080/00401706.1980.10486172 URL 摘要
Abstract The effect of system size and shape on the theoretical space-time autocorrelation function is described for first order STARMA models. Figures and tables are presented to assist in identification considerations which include model interpretation, patterns of the theoretical spacetime autocorrelation and partial autocorrelation functions, and initial estimation for the STAR(11) and STMA(11) models.
|
| [25] |
Variance of the sample-time autocorrelation function of contemporaneously correlated variables [J].https://doi.org/10.1137/0140010 URL [本文引用: 1] 摘要
An important part of the identification and diagnostic checking of space-time ARMA models is the evaluation of the significance of the autocorrelations of the observations and residuals, respectively. Since such tests are based on the calculated space-time autocorrelation function, it is necessary to know the variance of these correlations when in fact the underlying process is temporally independent. Previously the variance of the sample space-time autocorrelation function was developed for the case when the observed process consists of T independent observations of a vector random variable with mean zero and spherical variance covariance matrix, 2I (Pfeifer and Deutsch, J. Roy. Stat. Soc. B, 42 (1980)). This paper extends these results to the case of contemporaneously correlated variables. In this instance, G, the error covariance matrix of the observations, is nonspherical.
|
| [26] |
Urban road network modeling and real-time prediction based on house holder transformation and adjacent vector [M]
|
| [27] |
Some new indexes of cluster validity [J]. |
| [28] |
Space-time modeling of traffic flow [J].https://doi.org/10.1016/j.cageo.2004.05.012 URL Magsci [本文引用: 1] 摘要
<h2 class="secHeading" id="section_abstract">Abstract</h2><p id="">This paper discusses the application of space–time autoregressive integrated moving average (STARIMA) methodology for representing traffic flow patterns. Traffic flow data are in the form of spatial time series and are collected at specific locations at constant intervals of time. Important spatial characteristics of the space–time process are incorporated in the STARIMA model through the use of weighting matrices estimated on the basis of the distances among the various locations where data are collected. These matrices distinguish the space–time approach from the vector autoregressive moving average (VARMA) methodology and enable the model builders to control the number of the parameters that have to be estimated. The proposed models can be used for short-term forecasting of space–time stationary traffic-flow processes and for assessing the impact of traffic-flow changes on other parts of the network. The three-stage iterative space–time model building procedure is illustrated using 7.5 min average traffic flow data for a set of 25 loop-detectors located at roads that direct to the centre of the city of Athens, Greece. Data for two months with different traffic-flow characteristics are modelled in order to determine the stability of the parameter estimation.</p>
|
| [29] |
面向大规模数据的快速并行聚类划分算法研究 [J].https://doi.org/10.3969/j.issn.1002-137X.2012.01.030 URL 摘要
随着聚类分析中处理数据量的急剧增加,面对大规模数据,传统K-Means聚类算法面临着巨大挑战。为了提高传统K-Means聚类算法的效率,针对已有基于MPI的并行K-Means聚类算法和基于Hadoop的分布式K-Means云聚类算法,从聚心初始化和通信模式等入手,提出了改进思路和具体实现。实验结果表明,所提算法能大大减少通信量和计算量,具有较高的执行效率。研究结果可以为以后设计更好的大规模数据快速并行聚类划分算法提供研究依据。
Study of Fast Parallel Clustering Partition Algorithm for Large Data Sets. https://doi.org/10.3969/j.issn.1002-137X.2012.01.030 URL 摘要
随着聚类分析中处理数据量的急剧增加,面对大规模数据,传统K-Means聚类算法面临着巨大挑战。为了提高传统K-Means聚类算法的效率,针对已有基于MPI的并行K-Means聚类算法和基于Hadoop的分布式K-Means云聚类算法,从聚心初始化和通信模式等入手,提出了改进思路和具体实现。实验结果表明,所提算法能大大减少通信量和计算量,具有较高的执行效率。研究结果可以为以后设计更好的大规模数据快速并行聚类划分算法提供研究依据。
|
| [30] |
Traffic flow forecasting: comparison of modeling approaches [J].
|

/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}